Monitoreo de infraestructura
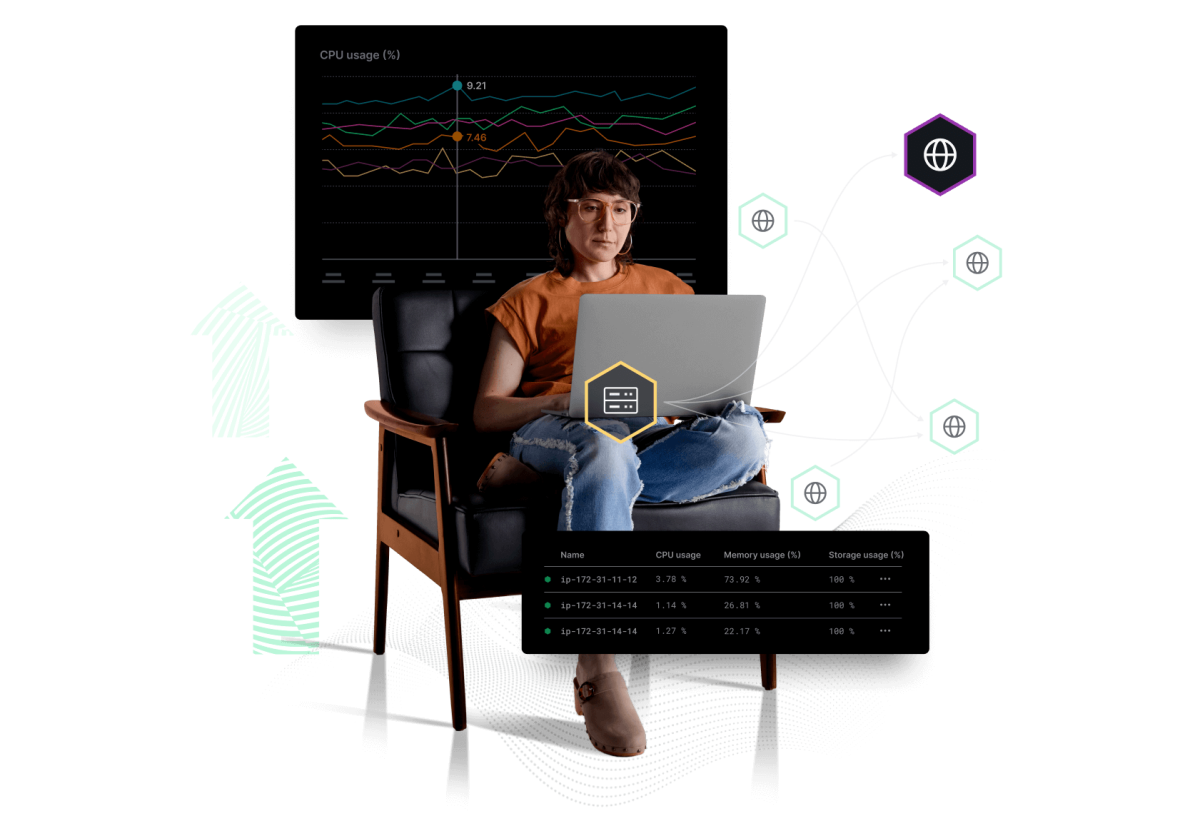
Un solo lugar para toda tu telemetría, sin dar cabida al tiempo de inactividad.
- Correlaciona la telemetría de la infraestructura, la aplicación y los usuarios finales.
- Detecta los problemas emergentes en tiempo real sin necesidad de alertas preconfiguradas.
- Visualiza el rendimiento de todo el sistema en una sola pantalla.
- Identifica las causas raíz visualizando las relaciones.
Quédate tranquilo. Este sistema de alerta temprana es para todo el sistema.
- Advierte los cambios en contexto y en tiempo real en todo tu sistema.
- Detecta de inmediato los cambios en las señales más importantes.
- Percibe el estado de todo el sistema en todos los hosts, máquinas virtuales, recursos de la nube, contenedores, servicios y aplicaciones.
- Reduce el riesgo en todo el flujo de trabajo de resolución de problemas.
Cuantifica el radio de impacto de todos los incidentes.
- Visualiza las relaciones y dependencias en toda la infraestructura y todas las aplicaciones.
- Aísla el origen de los problemas que impactan a varias entidades.
- Identifica el momento y la causa del impacto.
- Acelera la comprensión para aumentar la confianza.
Encuentra rápidamente las causas raíz con menos esfuerzo.
- Mantén el tiempo de actividad elevado con una experiencia unificada en una sola plataforma.
- Comprende la relación entre entidades, alertas, eventos, métricas de red y más.
- Visualiza todos los logs en contexto con un solo clic.
- Compara las señales doradas para varios componentes de infraestructura.
Paga solo por lo que necesitas,
no por un paquete de SKU
- Precios transparentes que se basan en usuarios
- 100 GB/mes de datos gratis
- $0.30 por GB a medida que creces
- Comenzar ahora gratis
¿Estás listo para comenzar?
Despliega los agentes y configura las integraciones.
Instrumenta todo con unos cuantos clics usando los inicios rápidos de New Relic Instant Observability.





nuestros productos.
Historias de los clientes


¿Tienes preguntas sobre el monitoreo de infraestructura? Tenemos las respuestas.
El monitoreo de infraestructura ofrece una observabilidad dinámica y flexible de toda tu infraestructura, desde los servicios que se ejecutan en la nube o en hosts dedicados hasta los contenedores que se ejecutan en Kubernetes. Correlaciona el estado y el rendimiento de todos tus hosts con el contexto de la aplicación, los logs y los cambios de configuración para lograr una observabilidad exitosa.
Los equipos de operaciones necesitan maneras más fáciles de solucionar problemas en los sistemas complejos, priorizar lo más importante e identificar las causas raíz más rápido.
Las cinco primeras tareas para comenzar son:
- Instalar el agente de infraestructura para los sistemas operativos Linux, macOS y Windows.
- Establecer las integraciones en la nube para Amazon Web Services (AWS), Azure y Google Cloud Platform.
- Echarle un vistazo a nuestras integraciones en el host para MySQL, NGINX, Cassandra y Kafka. Incluir las integraciones para Kubernetes y Prometheus.
- Integrar los logs del host con el agente de infraestructura.
- Crear dashboards personalizados para reunir toda la telemetría.
Sí. Con el monitoreo de infraestructura de New Relic, obtienes una visibilidad profunda de todos tus entornos ya sean on-premises, en la nube, híbridos o incluso en varias nubes.
El monitoreo de infraestructura de New Relic admite las integraciones con los proveedores de servicios en la nube de AWS, Microsoft Azure y Google Cloud Platform.
Nuestro agente de infraestructura admite varios sistemas operativos y se puede desplegar en cualquier lugar que tenga una conexión de Internet con visibilidad de New Relic.
Las métricas y señales doradas son bits de información sobre una entidad que consideramos son los más importantes para esa entidad. Nuestra experiencia de monitoreo de infraestructura te ayuda a analizar en contexto las entidades relacionadas, los logs, las alertas, las señales doradas, las métricas de red y el almacenamiento en una sola plataforma unificada para identificar las causas raíz y resolver los problemas más rápido.