Infrastructure Monitoring
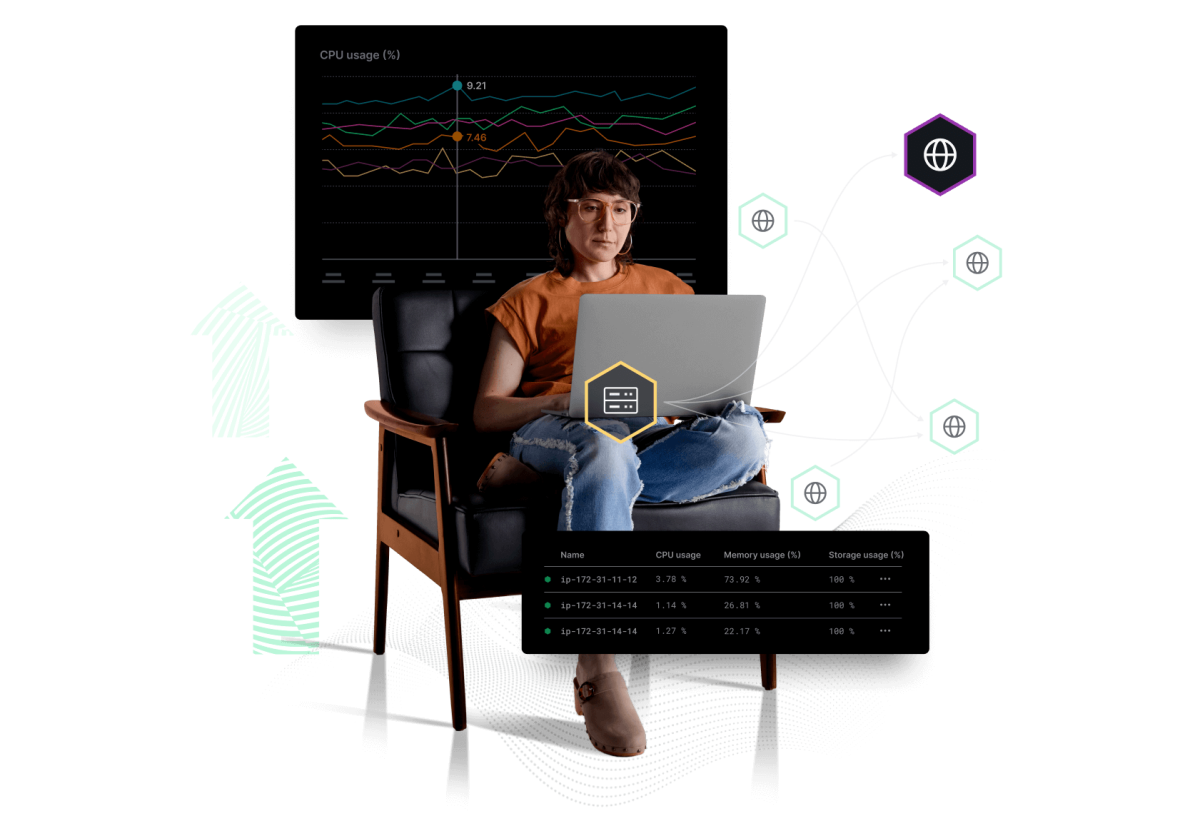
Telemetrie in, Downtime out
- Korrelation von Telemetrie zu Infrastruktur, Anwendungen und Endbenutzer:innen
- Ausmachen potenzieller Problemherde ohne Umschweife – ganz ohne Alert-Konfiguration im Vorfeld
- Zentrale Performance-Übersicht für sämtliche Systemkomponenten
- Visualisierung von Problemzusammenhängen zur punktgenauen Ursachenermittlung
Keine Hektik aufkommen lassen – mit einem Frühwarnsystem für Ihre Gesamt-Infrastruktur
- Transparenz mit Echtzeit-Kontext zu Veränderungen in Ihrem Gesamtsystem
- Direkte Erkennung von Abweichungen bei wichtigen Signalen
- Kompaktübersicht zum Health-Status sämtlicher Systemelemente – von Hosts, VMs und Cloud-Ressourcen bis hin zu Containern, Services und Anwendungen
- Minimierung von Risiken rund um Ihre Troubleshooting-Workflows
Auswirkungen und Schweregrad quantifiziert – für alle Incidents
- Visualisierung von Zusammenhängen und Abhängigkeiten über Infrastruktur und Anwendungen hinweg
- Isolieren von Problemursachen mit Auswirkungen auf mehrere Entitäten
- Identifikation von Auftrittszeitpunkt und Ursprung von Problemen
- Schnelles Zusammenfügen aller Puzzleteile zur Stärkung der Stabilität
Ihr direkter Weg zur Problemursache
- Unkomplizierte Uptime-Optimierung dank kompakt konsolidierter UX in einer Plattform
- Analyse von Zusammenhängen zwischen Entitäten, Alerts, Events, Netzwerk-Metrics und mehr
- Alle Log-Daten im Kontext – mit nur einem Klick
- Vergleich von goldenen Signalen über verschiedene Infrastrukturkomponenten hinweg
Nur das zahlen, was Sie auch nutzen –
kein SKU-Stückwerk
- Klare, nutzungsbasierte Preismodelle
- 100 GB/Monat Daten kostenlos erfassen
- $ 0,30/GB zur weiteren Skalierung
- Kostenlos starten
Bereit zum Starten?
Einfach Agents ausrollen und Integrationen einrichten.
Mit unseren Instant Observability Quickstarts instrumentieren Sie alles in Ihrem Stack mit nicht mehr als ein paar Klicks.





Kunden-Stories


Fragen zu Infrastructure Monitoring? Wir haben die Antworten.
Mit Infrastructure Monitoring erhalten Sie so flexible wie dynamische Observability für Ihre gesamte Infrastruktur – von Services in der Cloud über einzelne Hosts bis hin zu Kubernetes-Containern. Umgesetzt wird dies durch Korrelation von Health-Status und Performance mit Kontext zu Ihren Anwendungen, Logs und Konfigurationsänderungen.
Für Ops-Teams ist dies entscheidend, um Probleme in komplexen Systemen einfacher beheben, Prioritäten zielführender definieren und Ursachen schneller aufdecken zu können.
Dazu braucht es nicht mehr als fünf Schritte:
- Führen Sie zunächst die Installation des Infrastructure Agent für Linux, macOS oder Windows Betriebssysteme durch.
- Richten Sie dann unsere Cloud-Integrationen für Amazon Web Services (AWS), Azure und die Google Cloud Platform ein.
- Als Nächstes können Sie unsere On-Host-Integrationen für MySQL, NGINX, Cassandra und Kafka installieren. Nutzen Sie bei Bedarf auch die Integrationen für Kubernetes und Prometheus.
- Nun können Sie die Integration von Host-Logs mit dem Infrastructure Agent vornehmen.
- Et voilà! Damit sind Sie bereit, Ihre Telemetrie mittels Custom-Anpassungen in Dashboards zusammenzuführen.
Ja. New Relic Infrastructure Monitoring liefert umfassende Transparenz für On-Prem- und Cloud- ebenso wie für Hybrid- und Multicloud-Umgebungen.
Hierfür kann das Toolset mit Infrastruktur auf Basis von AWS, Microsoft Azure und der Google Cloud Platform integriert werden.
Der Infrastructure Agent bietet dabei Unterstützung für diverse Betriebssysteme: Zum Deployment ist lediglich eine internetbasierte Anbindung an New Relic vonnöten.
Goldene Signale und zugehörige Metrics beschreiben bestimmte Informationen zu einer Entität, die für diese als kritische Indikatoren gelten. Mit der Infrastructure Monitoring UI analysieren Sie kontextuelle Zusammenhänge zwischen Entitäten, Logs und Alerts, goldenen Signalen, Netzwerk-Metrics, -Prozessen und -Speicher komplett zentral in einer Plattform. So stoßen Sie rascher zur Ursache von Problemen und damit auch zu ihrer Lösung vor.