Monitoring d'infrastructure
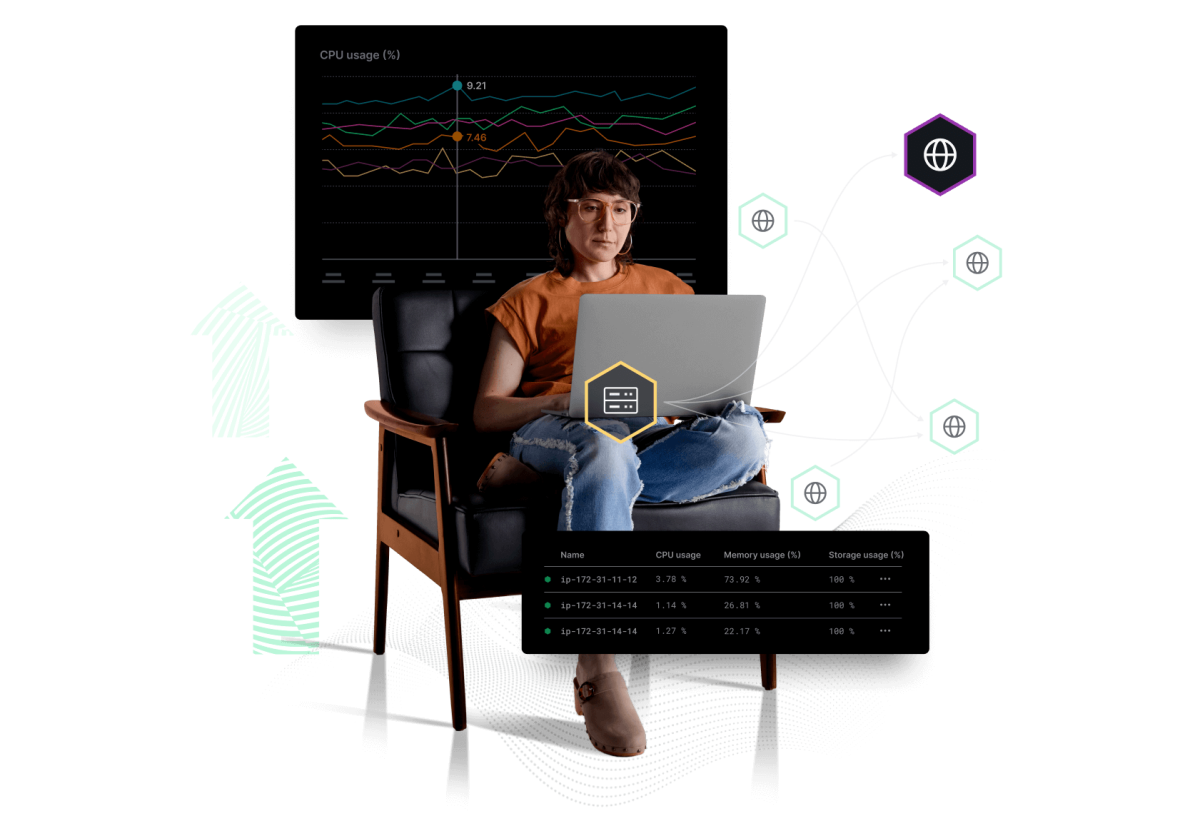
Un endroit pour toute votre télémétrie, mais aucune place pour les temps d'indisponibilité
- Corrélez les données télémétriques de l'infrastructure, des applications et des utilisateurs finaux
- Repérez les problèmes en temps réel sans nécessiter la préconfiguration des alertes
- Visualisez les performances de tout le système sur un seul écran
- Trouvez la source d'un problème en visualisant les corrélations.
Restez zen. Ce système de détection précoce couvre tout votre domaine.
- Visualisez les changements dans leur contexte en temps réel sur tout votre domaine.
- Détectez immédiatement les changements sur les signaux les plus importants.
- Détectez l'état de santé de tout le système sur tous les hôtes, machines virtuelles, ressources cloud, conteneurs, services et applications.
- Réduisez les risques sur tous vos workflows de dépannage.
Quantifiez le rayon d'impact de chaque incident
- Visualisez les relations et dépendances sur toute l'infrastructure et dans toutes les applications.
- Isolez la source des problèmes qui impactent plusieurs entités.
- Identifiez le moment et la cause de l'incident.
- Accélérez la clarté pour augmenter la fiabilité.
Trouvez rapidement les causes profondes tout en réduisant la charge de travail.
- Maintenez les temps de disponibilité avec une expérience uniforme sur une plateforme unique.
- Comprenez les relations entre les entités, les alertes, les événements, les métriques réseau, etc.
- Explorez tous les logs dans leur contexte en un clic.
- Comparez les signaux dorés pour de multiples composants d'infrastructure.
Une tarification qui s'adapte à vos besoins
- Tarification à l'utilisateur transparente
- Gratuit : 100 Go/mois de données
- 0,30 USD/Go à mesure que vous évoluez
- Démarrez immédiatement et gratuitement
Êtes-vous prêt à commencer ?
Déployez les agents et définissez les intégrations.
Instrumentez tout en quelques clics en utilisant les quickstarts de New Relic Instant Observability.





Témoignages


Vous avez des questions sur le monitoring d'infrastructure ? Nous avons les réponses.
Le monitoring d'infrastructure offre une observabilité flexible et dynamique de toute votre infrastructure, des services exécutés dans le cloud ou sur des hôtes dédiés jusqu'à des conteneurs exécutés dans Kubernetes. Corrélez l'état de santé et les performances de tous vos hôtes avec le contexte de l'application, les logs et les modifications de la configuration pour une observabilité réussie.
Les équipes Ops doivent disposer de moyens plus simples pour dépanner les systèmes complexes, prioriser les éléments essentiels et identifier les causes profondes plus rapidement.
Les cinq premières tâches pour bien démarrer sont les suivantes :
- Installez l'agent d'infrastructure pour les systèmes d'exploitation Linux, macOS et Windows.
- Établir les intégrations pour Amazon Web Services (AWS), Azure et Google Cloud Platform
- Consulter nos intégrations sur hôte pour MySQL, NGINX, Cassandra et Kafka Inclure les intégrations Kubernetes et Prometheus
- Intégrer les logs de l'hôte avec l'agent d'infrastructure
- Créer des dashboards personnalisés pour regrouper toute la télémétrie
Oui. Avec le monitoring d'infrastructure New Relic, vous obtenez la visibilité en profondeur de tous vos environnements, qu'ils soient sur site, cloud, hybrides ou même multi‑cloud.
Le monitoring d'infrastructure New Relic prend en charge les intégrations vers des prestataires de services cloud AWS, Microsoft Azure et Google Cloud Platform.
Notre agent d'infrastructure prend en charge de nombreux systèmes d'exploitation et peut être déployé partout où il existe une connexion Internet pour assurer la visibilité vers New Relic.
Les métriques et les signaux dorés sont des bits d'informations sur une entité que nous considérons comme étant la plus importante pour cette entité. L'expérience de monitoring d'infrastructure que nous proposons vous aide à analyser dans leur contexte les entités, les logs, les alertes, les signaux dorés, les métriques réseau, les processus et le stockage. En outre, la plateforme est uniformisée et unifiée et vous permet d'identifier les causes et de résoudre les problèmes plus rapidement.