As technology becomes increasingly complex, it’s more critical than ever to see across your entire software system and get traceability through your entire stack. To do so, you need to collect four key data types: metrics, events, logs, and traces. But it’s not enough to gather all of the data. You need to understand the relationships among those data points to solve specific problems quickly.
New Relic automatically creates and maintains visibility into those relationships. With Full-Stack Observability, you can easily visualize, analyze, and troubleshoot your entire software stack in one connected experience. Understand system health in context—from logs, infrastructure, applications, and end-user experience data—with UI experiences that automatically surface issues. Teams responding to on-call incidents won’t have to switch tools to dig into different parts of the stack, eliminating toil and blind spots, and ultimately driving more seamless enduser experiences.
In addition to the deep visibility provided by our monitoring capabilities (APM, Infrastructure Monitoring, Serverless Monitoring, and Digital Experience Monitoring), Full-Stack Observability also includes:
- New Relic Explorer. Visualize and explore all your telemetry data in one place so you can see the health of your systems at a glance, discover unknowns, and get everything back up and running before customers notice.
- New Relic Lookout. See and prioritize changes across all your data regardless of source, zoom in for deeper understanding, and uncover blind spots and unknown relationships—all with zero configuration.
- New Relic Navigator. Visualize the entire estate in a highly dense honeycomb view to quickly assess the health of your environment.
- Distributed tracing. See the entire journey your requests take as they travel through distributed systems.
- New Relic Edge with Infinite Tracing. Accept and analyze 100% of your span data with tail-based sampling.
- Logs in context. Enrich log data with full context into high-level events.
- Kubernetes cluster explorer. Visualize the health and performance of Kubernetes clusters.
- Workloads. Visualize the status of complex systems and accurately pinpoint problems.
Full-Stack Observability Use Cases
Full-Stack Observability helps solve problems across the full estate—all in one place.
1. Troubleshoot the full stack faster
Banish blind spots. Troubleshooting uptime or performance issues with out-of-the-box visualizations gives you context across the various components that make up your service—without having to navigate across different solutions. A single view of what’s happening across your environment lets you resolve issues faster.
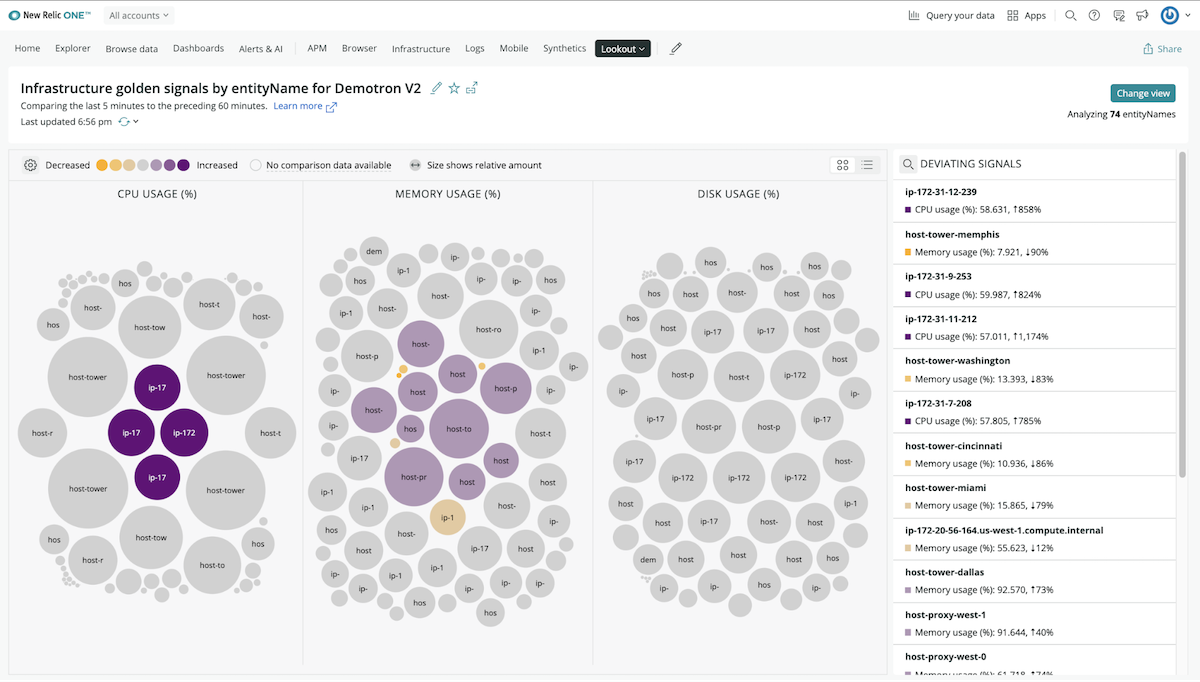
See all of your data in one place with New Relic Lookout.
2. Debug with precision
Detect, triage, and eliminate errors faster. Prioritize errors with the highest customer impact, and receive code-level visibility of stack traces and error details—down to the log level—so you can quickly understand the issue, trace its impact throughout the stack, recreate it locally, and resolve it.
3. Optimize customer experience
Benchmark and improve end-user experience on web and mobile. Whether you’re analyzing user performance metrics, troubleshooting crashes on native mobile apps, or measuring API and third-party performance, Full-Stack Observability helps you understand how the changes you’re making to web and mobile properties affect your customers.
4. Embrace multi-cloud with confidence
As you tackle strategic initiatives such as cloud adoption, rest easy knowing that you have dynamic visibility into system components. With service maps, you can unearth how your system’s various components relate, so you’re sure to do a full accounting in advance of a migration. As you adopt new cloud architectures such as microservices or services such as serverless functions, you can monitor performance and establish custom alerts to tune processes.
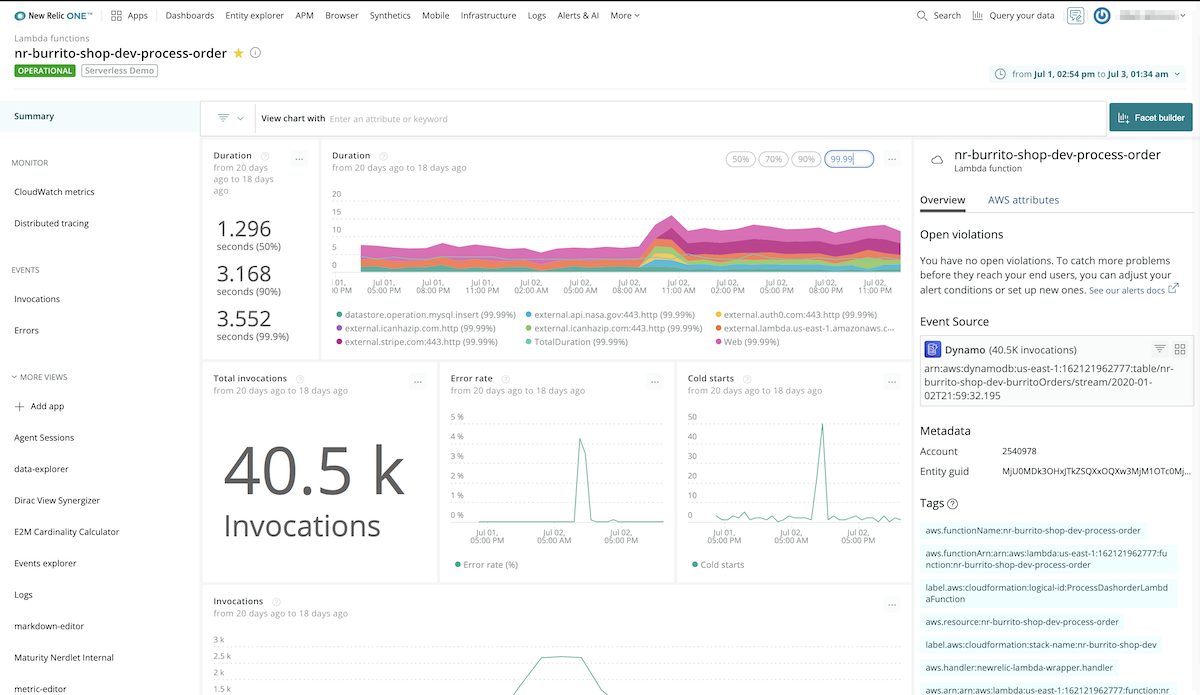
Troubleshoot faster with in-depth performance monitoring for your serverless functions.
5. Foster a DevOps culture of experimentation
Allow DevOps teams to release features more frequently and with more precision by giving them visibility into how deploys impact performance. Full-Stack Observability reveals the impact of changes to code and infrastructure immediately, minimizing the effort to identify the cause of service degradations.
“What New Relic means to me and my team is how it delivers a modern, enterprise-grade, 360-degree visibility of our entire technology landscape.”
—Difa Niculescu, IT Director, Tandem Bank
Observability Made Simple
You get all of this and more with Full-Stack Observability in New Relic One, backed by the Telemetry Data Platform’s scalability and supported with transparent, predictable, user-based pricing. Empower your teams and free up more time to do what you love: building and maintaining software.
Explore all the capabilities Full-Stack Observability offers, and try it for free.


