Introduction
Today, application and data infrastructures are as complex as they’ve ever been, creating an abundance of data about their internal workings. As such, monitoring practices have evolved, leading DevOps teams, application developers, and operations and infrastructure teams to adopt observability best practices. One crucial practice of observability is to instrument everything in your stack.
However, trying to handle all this data on your own will only present another set of challenges. Are you recording the right data in the right formats? Is your data pipeline big enough to handle the load as your demand on your software increases? At New Relic, we believe observability should reduce anxiety instead of adding to it.
To that end, you need a single observability platform, with a unified database, that:
- Gathers all your telemetry data in one place, giving you a connected view of all the data points in your system, so you can identify, understand, and resolve the issues that impact your business
- Is built on a flexible schema, so you can get fast answers to questions that you never had to ask before
- Scales as your business grows, and does so without limits to support any unpredictable demands on your business
Such capabilities are the defining functions of Telemetry Data Platform.
Telemetry Data Platform, the world’s most powerful platform to analyze operational data
Telemetry Data Platform is the powerhouse driving New Relic One. We call it the world’s most powerful telemetry platform for a reason: Its median query response time is lightning-fast (60 milliseconds), and its 99% percentile response time is less than two seconds. For very large queries—those scanning over 50 billion records—99% finish in less than 30 seconds. Telemetry Data Platform ingests over 1 billion data points per minute, so when any customer experiences increased demand, Telemetry Data Platform handles the incremental hundreds of millions of data points with ease.
Behind the scenes, Telemetry Data Platform is a very large distributed system—a multi-tenant cloud service on which a large query will run on thousands of CPU cores concurrently, allowing it to process billions of records in seconds.
We designed Telemetry Data Platform to scale without limits to support the unpredictable demand of our customers around the globe. As our customer base has grown over the past decade, from retail to entertainment, apparel to healthcare, and gaming to e-commerce, we have scaled Telemetry Data Platform. And because of its multi-tenant architecture, our smallest customers benefit from the same massive computing resources as our largest customers.
Whether you are starting on a single host, a single app, or running an enterprise with tens of thousands of hosts and application instances, Telemetry Data Platform supports your needs. As your business and data grow, Telemetry Data Platform will scale to support your business requirements.
So, how does Telemetry Data Platform do all this? In this white paper, we explain:
- The data model behind Telemetry Data Platform
- The telemetry data types stored in Telemetry Data Platform
- The SQL-like query language that makes querying large amounts of data a breeze
- The key resources for learning how to ingest and query Telemetry Data Platform
How Telemetry Data Platform Is Purpose-Built for Time Series Data
A good database provides so much more than data storage and retrieval. A good database provides value-add services, like analytics and aggregation, so teams can offload heavy computing to the database server. A database’s query functionality is another critical aspect of its utility, and that query power is dictated by its data model.
Telemetry Data Platform stores time series data—a series of data points indexed in time order—which is an important class of telemetry data. In this section, we summarize three different models for time series data and explain why we settled on the one that works best: a relational model with a flexible schema.
Note: In this section, the examples require discussion of metrics, aggregated sets of measurements grouped or collected at regular intervals. We’ll further discuss metrics—as well as other telemetry data types—and their relationship to Telemetry Data Platform later in this white paper.
One-dimensional, time series-centric model: Simply not enough
As we defined it above, time series data is data that’s indexed in a series of particular time periods or intervals.
Consider the following example, where each row represents a time series. Each time series is identified by a metric name and several tags.
| Metric name | Tags | Time series (time:value pairs) |
|---|---|---|
|
cpuTime |
host=server1, dataCenter=east | t1:22, t2:14, t3:34, ... |
| cpuTime | host=server2, dataCenter=east | t1:37, t2:11, t3:94, ... |
| responseTime | database=mysql, data=inventory | t1:15, t2:45, t3:90, t4:57... |
| ... | ... | ... |
A typical query API provides mechanisms to select time series by name or filter and to “group by” tags. If you need to query a single metric name, this works well, but if you need to query multiple metric names at once, it’s not so useful.
For example, imagine you have two metrics: cpuTimeSpent and numRequestsProcessed. Suppose you want to observe per request cpu cost change over time. Conceptually, doing so is just a simple division: cpuTimeSpent / numRequestsProcessed. But expressing this formula to query time series data is not easy. In many systems, the client will retrieve both time series, and then do the division on the client side. In fact, we’ve seen examples in which it takes 20 lines of code to do a retrieval and division like this. (Some databases use vector matching to deal with multiple metrics. Functionally, this works, but it requires mental acrobatics from the user.)
From a programming language point of view, the shortcoming of a time series-centric model is that it only supports one-dimensional array; in other words, a time series is an array indexed by one dimension—time. When dealing with multiple arrays, any system that uses this model has to resort to convoluted mechanisms, like vector matching to correlate elements in the arrays. This isn’t great for applications: “While these systems provided some of the benefits of a database system, they lacked many traditional database features that application developers often rely on,” write the authors of Google’s Spanner: Becoming a SQL System. “A key example is a robust query language, meaning that developers had to write complex code to process and aggregate the data in their applications.”
Relational model, fixed schema: Too many tables to stitch together
Because querying one-dimensional data imposes severe limitations, some databases use a relational model for time series data. In this model, each data point is presented as a row in a relational table with the timestamp and tags presented in columns. For example:
| time | host | dataCenter | cpuTime | memoryUsed |
|---|---|---|---|---|
| t1 | server1 | east | 17 | 2078 |
| t2 | server2 | east | 48 | 3810 |
| ... | ... | ... | ... | ... |
With this approach, you get full power from SQL, but you need to explicitly run a create table statement for each metric and tag schema. This is more than just inconvenient: If you have a large number of schemas, you’ll have a large number of tables, which stresses the database. Similarly, if you run a schema change (alter table), you’ll have performance problems at scale.
You’ll also find that multi-metric queries are still a problem. Although this model allows multiple metrics in one table (as shown in the example above), there will be times when you need to query across tables because one schema does not fit all data.
Consider this scenario: You have a host table for host metrics and an application table for application metrics, such as numRequests. To compute cpuTime / numRequests, you’ll need to do a SQL join on the time column to stitch the two tables together. Unless rows in the two tables always have exactly matching timestamps, you’ll need to apply a time_bucket() function on the time column to snap timestamps to the time bucket boundary. For example:
select time_bucket(‘1 hour’, hostTable.time) as bucketTime, sum(cpuTime) / sum(numRequests) from hostTable, applicationTable where time_bucket(‘1 hour’, processTable.time) = bucketTime group by bucketTime order by bucketTime
This example shows the non-intuitive way of using group by on time to generate a time series. In contrast, the New Relic Query Language (NRQL)—which we provide more detail about below—uses an intuitive timeseries clause to query time series across multiple tables.
Telemetry Data Platform's secret sauce: Relational model with flexible schema
To solve the problem of multiple tables, Telemetry Data Platform uses a relational model with a flexible schema. In this model, rows in a table don’t have to use the same schema. In fact, to be even more user friendly, there is no create table statement at all. When Telemetry Data Platform's database ingests a new column, it’s automatically added to the table’s schema. Essentially, Telemetry Data Platform uses the union of schemas from all rows as the table schema.
In Telemetry Data Platform’s flexible schema (as shown in the following example), each row represents a data point. Row 1 holds the cpuTime metric, with host and dataCenter tags. Row 2 holds the appRequests metric, with host and appName tags. (The metricName column is a metadata column, which we’ll explain in the “Schema Introspection” section of this document.)
| time | metricName | cpuTime | host | dataCenter | appName | appRequests |
|---|---|---|---|---|---|---|
| t1 | cpuTime | 27 | server1 | east | ||
| t2 | appRequests | server1 | invoiceApp | 78 | ||
| ... | ... | ... | ... | ... | ... | ... |
If a column is not present on a row, its value is null (illustrated by the gray cells). The “is null” and “is not null” operators work as usual. For example, to get metric names of all metrics with a host tag, you can run select uniques(metricName) where host is not null.
From a programming language point of view, this is a two-dimensional array. Because every metric is present on the table schema, you can compose fairly simple multi-metric queries. For example, to use NRQL to produce time series data of per request CPU cost, you could run:
From Metric select sum(cpuTime) / sum(appRequests) timeseries
In the monitoring industry, “dimensional” metrics refer to metric data with attributes attached as key:value pairs, such as duration-related attributes (start time, end time), entity ID, region, host, etc. This amount of detail allows for in-depth analysis and querying. Telemetry Data Platform supports dimensional metrics from the following sources:
- Open source integrations
- New Relic’s Telemetry SDKs
- New Relic’s Metric API (the underlying API used by the tools above)
Schema introspection: Metadata is a first-class citizen in New Relic
When Telemetry Data Platform ingests data, it automatically generates table schema based on that data using the keyset() function for schema introspection, which returns column names and types. The function is called “keyset” because a row can also be seen as a list of key:value pairs, where both keys and values are represented as column names, and the function returns the key set.
The keyset() function takes rows as input and produces a schema (a list of columns with name and type) as output, similar to object introspection in some programming languages. Together with the MetricName column (available in the “Metric” table only), Telemetry Data Platform provides rich metadata query features, and users can apply the full power of NRQL analytics on schema introspection.
Here are just a few examples gathered with NRQL:
| NRQL query | Usage |
|---|---|
select keyset() from myTable |
This query returns the schema of rows timestamped in the past hour; since 1 hour ago is the default time window for a query. |
select keyset() from myTable since 8 days ago until 7 days ago |
This query asks, “What was the schema like a week ago?” Since it’s a standard select statement, you can use the standard time range clauses. |
select keyset() from myTable where hostname is not null |
This query returns the schema of rows with a hostname column. You can use the standard where clause. |
select keyset() from Metric where metricName = ‘cpuTime’ |
This query returns the schema for the given metric name only. This is a handy way to get the tag set for a metric name. |
select keyset() from Metric facet metricName |
Facet is the NRQL equivalent of group by. This query returns the schema of many metric names, grouped by metric name. |
select uniqueCount(metricName) from Metric |
This query tells you how many unique metric names you have. |
select uniques(metricName) from Metric where metricName = ‘cpu%’ |
This query returns all metric names starting with cpu. |
select uniques(metricName) from Metric where hostname = ‘server1’ |
This query returns all metric names with a hostname tag of server1. |
In the next section, we’ll describe the main data types stored in Telemetry Data Platform.
Unified Telemetry: The Key Data Types of Telemetry Data Platform
In the age of observability, you need to instrument everything and view all your telemetry data in one place. At New Relic, we believe that metrics, events, logs, and traces (or MELT for short) are the essential data types of observability. When you instrument everything and use MELT to form a fundamental, working knowledge of the relationships and dependencies within your system, as well as its detailed performance and health, you’re practicing observability. But to form those connections, you need a single unified database built on a flexible schema, like that of Telemetry Data Platform.
Telemetry Data Platform supports the four main telemetry data types:
-
Metrics: An aggregated set of measurements grouped or collected at regular intervals
-
Events: Discrete occurrences happening at a moment in time in your system
- Logs: Time-stamped text-based messages, typically arranged as structured data
- Traces: Known as distributed traces, these are samples of discrete and irregular causal chains of events (or transactions) between different components in a microservices ecosystem
For a deeper dive into the core data types, check out MELT 101: An introduction to the four essential telemetry data types.
With New Relic, these telemetry data types:
-
Are stored in one place—Telemetry Data Platform—with different data types in different tables.
-
Are unified under one data model—a relational model with a flexible schema.
-
Can all be queried by the same language—NRQL.
NRQL + telemetry data = a unified user experience
With Telemetry Data Platform, you get a consistent data model and query language across each telemetry data type. And it’s not just for querying the data—many parts of the platform have NRQL integrated within their APIs. For example, you can define Alert conditions with NRQL, and NRQL is used to create events-to-metrics rules. This power and flexibility makes your day-to-day work much easier.
Now, let’s look at how each of these data types are used in Telemetry Data Platform.
Scaling big metrics
Metrics are a staple in the world of telemetry. They work well for large bodies of data, or data collected at regular intervals, when you know what you want to ask ahead of time.
Scale matters, and Telemetry Data Platform's scale is hard to beat
Telemetry Data Platform’s analysis capabilities shine at scale. Let’s say you work for a big enterprise, with tens of thousands of hosts across multiple data centers, and you want to find out which of your data centers have the heaviest load. You could use the following query: select average(cpuPercent) from Metric facet dataCenter since 7 days ago. Given that your thousands of hosts are spread across multiple data centers, the query needs to aggregate the cpuPercent metric from all the hosts, which requires accessing more than 10,000 time series. In the world of metrics and telemetry data, this is the well-known “high cardinality” problem, where high volumes of unique values in a dataset can outpace a database’s ability to analyze the data. Most time series databases, which are designed to chart only a few time series, struggle to perform these types of queries. But Telemetry Data Platform easily returns results in milliseconds.
Telemetry Data Platform supports the following metric types:
| Metric | Description | Available query functions |
|---|---|---|
gauge |
Represents a value that can increase or decrease with time. Examples of gauges include the temperature, CPU usage, and memory. For example, there is always a temperature, but you are periodically taking the temperature and reporting it. |
|
count |
Measures the number of occurrences of an event. Examples include cache hits per reporting interval and the number of threads created per reporting interval. Examples include cache hits per reporting interval and the number of threads created per reporting interval. |
|
summary |
Used to report pre-aggregated data, or information on aggregated discrete events. Examples include transaction count/durations and queue count/durations. |
|
Pre-aggregating metrics into longer time windows to optimize queries is a common practice, and Telemetry Data Platform takes full advantage of this technique. For example, Telemetry Data Platform produces 1-minute, 5-minute, 15-minute, 1-hour, 6-hour, and 1-day aggregates of metric data. At query time, the query worker chooses the optimal roll-up window for the given time horizon. For example, a year-long query will use 1-day roll-ups, whereas a 12-hour query leverages 1-minute roll-ups.
Getting insight into discrete occurrences with events
Events are a critical telemetry data type for observability, providing discrete, detailed records of significant points for analysis. Common examples of events include deployments, transactions, and errors. Monitoring events helps you do fine-grained analysis in real time.
With events in Telemetry Data Platform, you get:
- Free-form ingestion: In addition to events generated by New Relic APM agents, you can use the events API to insert custom event data into any table with any schema in Telemetry Data Platform.
- NRQL queries: Because events are stored in Telemetry Data Platform, you have the full power of NRQL to interrogate them. In contrast, many other telemetry systems treat events as second-class citizens, with only support for simple insert and retrieval.
- The ability to generate metrics from events: The events-to-metrics service aggregates events into metrics to reduce retention requirements and make queries even faster. Simply define a rule to generate metrics from your events, and instead of storing thousands of events per second, one metric record per minute will track your transaction performance.
Custom events
Custom events can be used in all sorts of creative ways, and they’re great for tracking high-volume events, such as application transactions. For example, you can insert an event every time a user places an order on your website, recording the user ID, the dollar amount, the number of items bought, and the processing time. Such granular data provides the ability to investigate individual transactions, going beyond the capabilities of aggregated metrics. Because each transaction is a discrete event, you can analyze the distributions of any given attribute, including the correlation between attributes. The only requirement for custom events in Telemetry Data Platform is that each row must have a timestamp.
New Relic agent events
New Relic agents create events, which you can query to create your own charts. For example, query Transaction events from APM, and PageView events from New Relic Browser to perform deeper analysis than what you could from default charts. Use the query API to write New Relic One applications based on the custom events you send to Telemetry Data Platform.
The following examples show how you can run NRQL queries on custom event data tracking orders placed on your website:
| Query | Usage |
|---|---|
select histogram(orderDollarAmount, 1000) from Order |
Get a distribution of the order size. |
select uniqueCount(userId) from Order |
Find out how many unique users placed orders. |
select average(processingTime) from Order facet cases(where numItems < 10, where numItems < 50, where numItems < 100) |
Find out if the number of items purchased have an impact on processing time. (This query analyzes correlation between two fields. You can’t do this with two metrics because the transaction level correlation is lost when the numbers are aggregated into two metrics.) |
select average(processingTime) from Order timeseries since 7 days ago |
Find out the average processing time of all orders. (You can get aggregation on fields, just like with metrics. If you had a processingTime metric in the “Metric” table, the query to get this time series from the Metric table would be identical, except that you would be selecting from the Metric table. This showcases the unified query interface for events and metrics.) |
Slicing and dicing logs
Logs, the original telemetry data type, are lines of text a system produces when certain code blocks are executed. Developers rely on logs for troubleshooting their code, databases, caches, load balancers, or older proprietary systems that aren’t friendly to in-process instrumentation.
New Relic Logs in Context writes to Telemetry Data Platform’s Log table, from which your log data is accessible via NRQL. Querying logs is no different than querying events—you have the full analytical power of NRQL at your fingers.
Similar to dimensional metrics, log lines have tags, and each tag is represented as a column in the Log table. The “message” column itself contains log text. Arbitrary tags can be specified upon log ingestion.
| Timestamp | Host | Message |
|---|---|---|
2020-02-18 18:38:15 |
vpn15c |
%ASA-6-725007: SSL session with client outside:38.108.108.47/35770 to 203.53.240.37/443 terminated |
2020-02-18 18:38:15 |
vpn15c |
%ASA-6-725001: Starting SSL handshake with client outside:38.108.108.47/35770 to 203.53.240.37/443 for TLS session |
2020-02-18 18:38:15 |
vpn15c |
%ASA-6-725016: Device selects trust-point OUTSIDE for client outside:38.108.108.47/35770 to 203.53.240.37/443 |
Tracing spans
Traces are samples of discrete and irregular causal chains of events (or transactions) between different components in a microservices ecosystem. Stitched together, traces form special events called “spans,” which provide the mechanism to track the causal chain. To do so, each service passes correlation identifiers, known as “trace context,” to each other, and this trace context is used to add attributes on the span.
New Relic distributed tracing writes to the “Span” table in Telemetry Data Platform, with each row in the table representing a span:
| Timestamp | EventType | TraceID | SpanID | ParentID | ServiceID | Duration |
|---|---|---|---|---|---|---|
2/21/2019 15:34:23 |
Span |
2ec68b32 |
aaa111 |
Vending Machine | 23 | |
2/21/2019 15:34:22 |
Span |
2ec68b32 |
bbb111 |
aaa111 |
Vending Machine Backend | 18 |
2/21/2019 15:34:20 |
Span |
2ec68b32 |
ccc111 |
bbb111 |
Credit Card Company | 15 |
2/21/2019 15:34:19 |
Span |
2ec68b32 |
ddd111 |
ccc111 |
Issuing Bank | 3 |
As you’d expect, you can query span data in Telemetry Data Platform with NRQL. See our documentation for some example queries.
NRQL: Your Gateway to Telemetry Data Platform
New Relic Query Language (or NRQL, pronounced “Nerkel”) is the query language for interacting with Telemetry Data Platform. It’s an SQL-like language with extensions to make time series queries fast and easy, with a number of clauses and functions you can use to explore your data on your terms.
New Relic uses NRQL behind the scenes to build many of the out-of-the-box charts and dashboards present in tools like New Relic APM and New Relic Infrastructure. Users can also use basic or advanced NRQL queries to create charts with the New Relic One chart builder and for custom New Relic One applications. In many cases, writing a query to create a chart is as simple as writing one line, and query auto completion in chart builder makes writing queries even easier.
We modeled NRQL after SQL so that users already familiar with SQL will essentially already understand how to use NRQL. NRQL and SQL syntax overlap by almost 95%, with the remaining 5% representing time series syntax.
Below are a few notable times series extensions in NRQL, shown with example queries and charts:
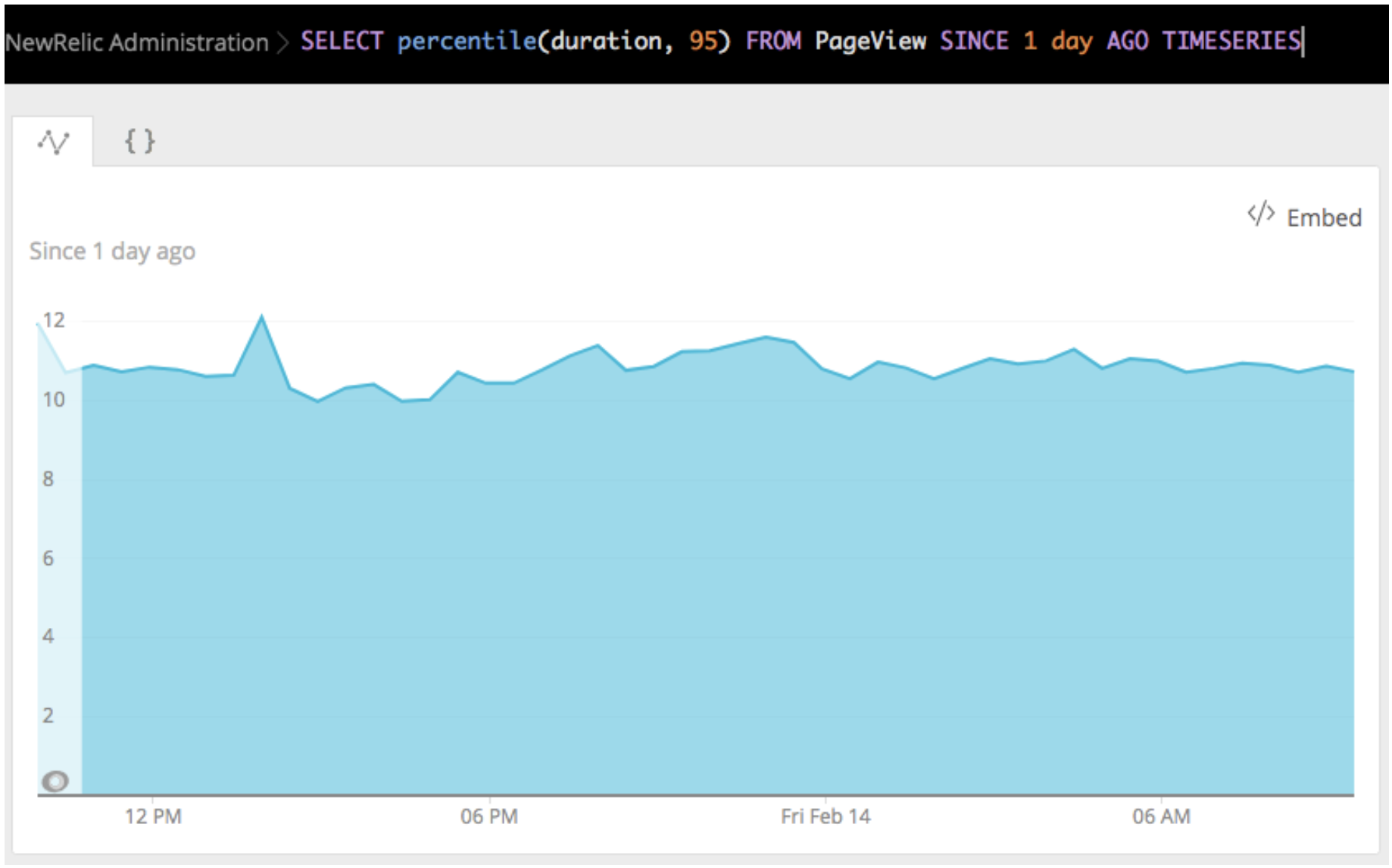
TIMESERIES: This clause produces data points indexed by timestamp and is available to most queries in NRQL. Here’s an example of graphing the 95th percentile of thedurationfield over time:SELECT percentile(duration, 95) FROM PageView SINCE 1 day AGO TIMESERIES
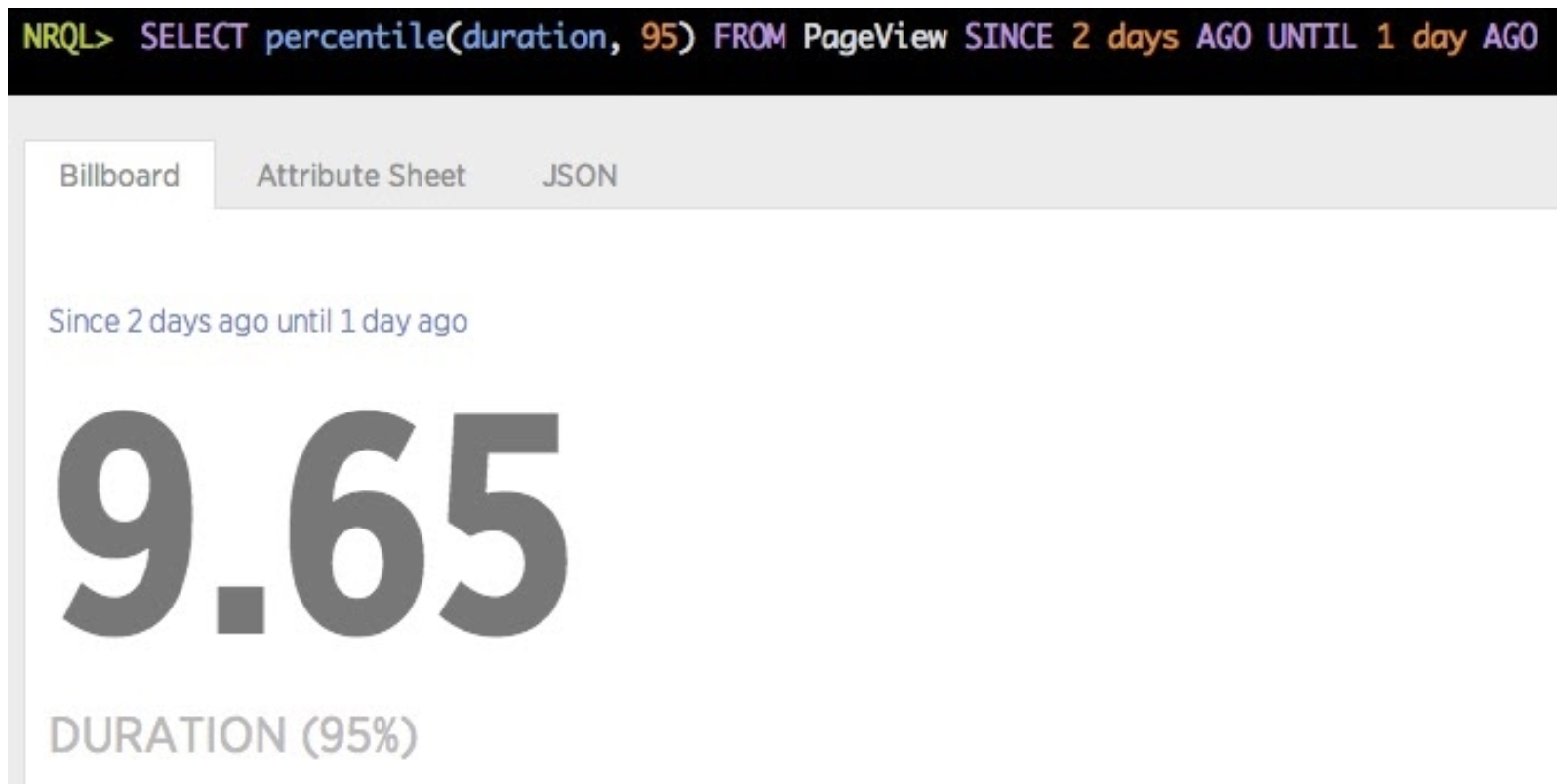
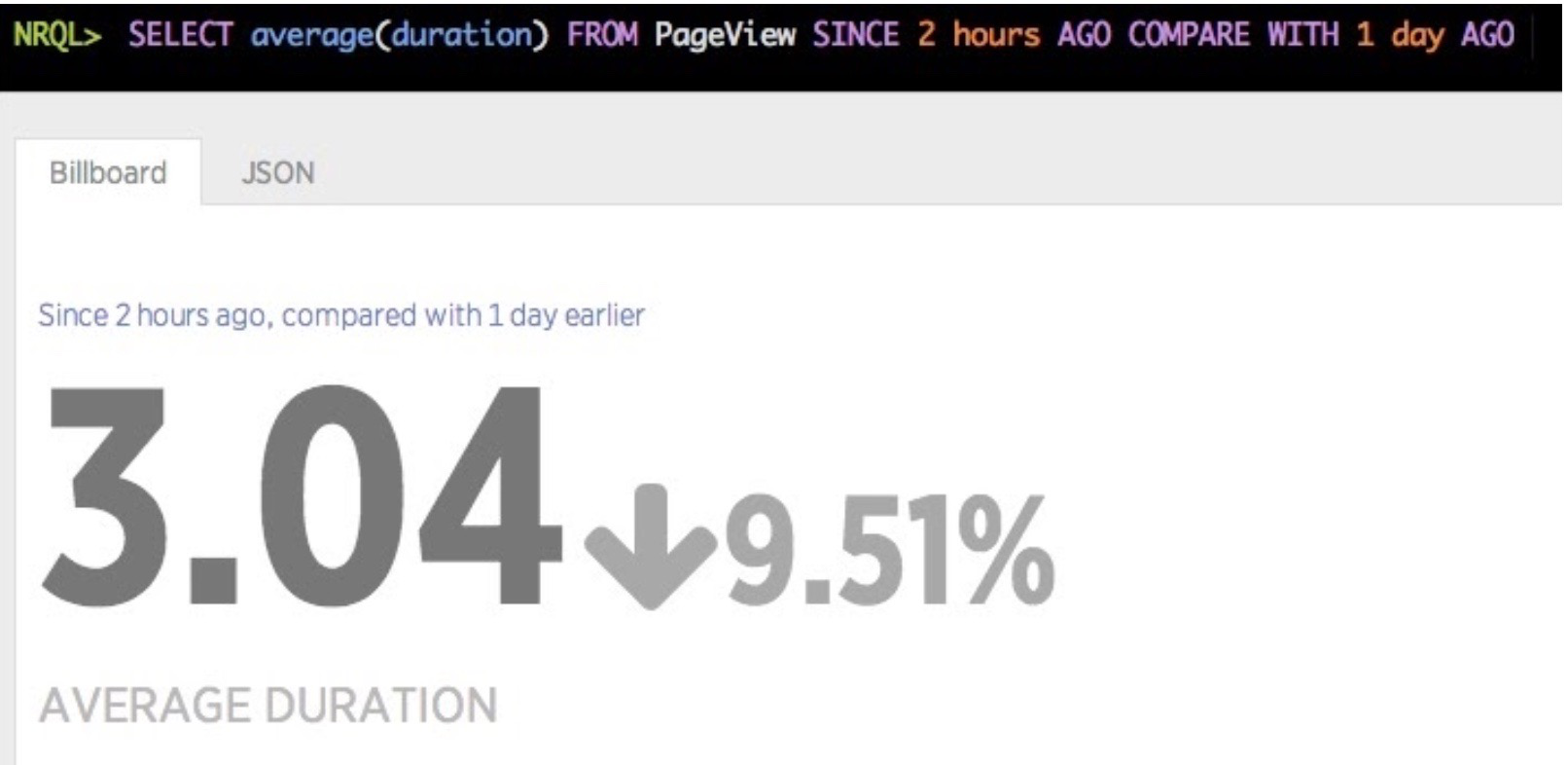
COMPARE WITH: This clause produces two sets of output—one derived from theSINCE/UNTILwindow and one derived from that same window shifted into the past, for comparison purposes. Here’s an example of comparing session count between today and yesterday:SELECT average(duration) FROM PageView SINCE 2 hours AGO COMPARE WITH 1 day AGO
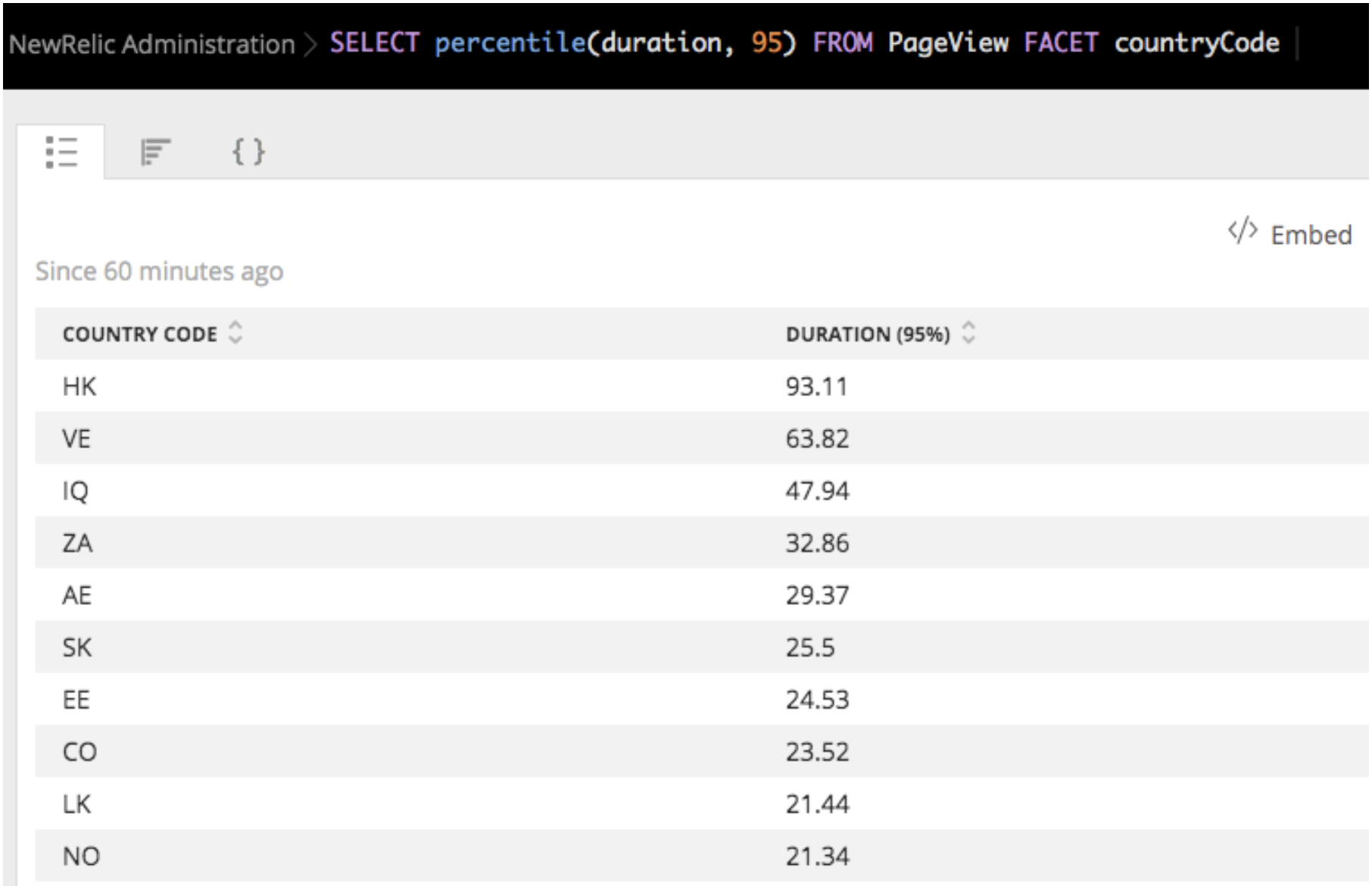
FACET: This clause is NRQL’s version ofgroup by, tuned for time series data. This query gives you the geographic breakdown of your visitors by country, auto sorted by the groups’ page view durations:SELECT percentile(duration, 95) FROM PageView FACET countryCode
For further reading on NRQL queries, see NRQL User Manual and Secrets of a NRQL Wizard.
How Telemetry Data Platform achieves millisecond performance
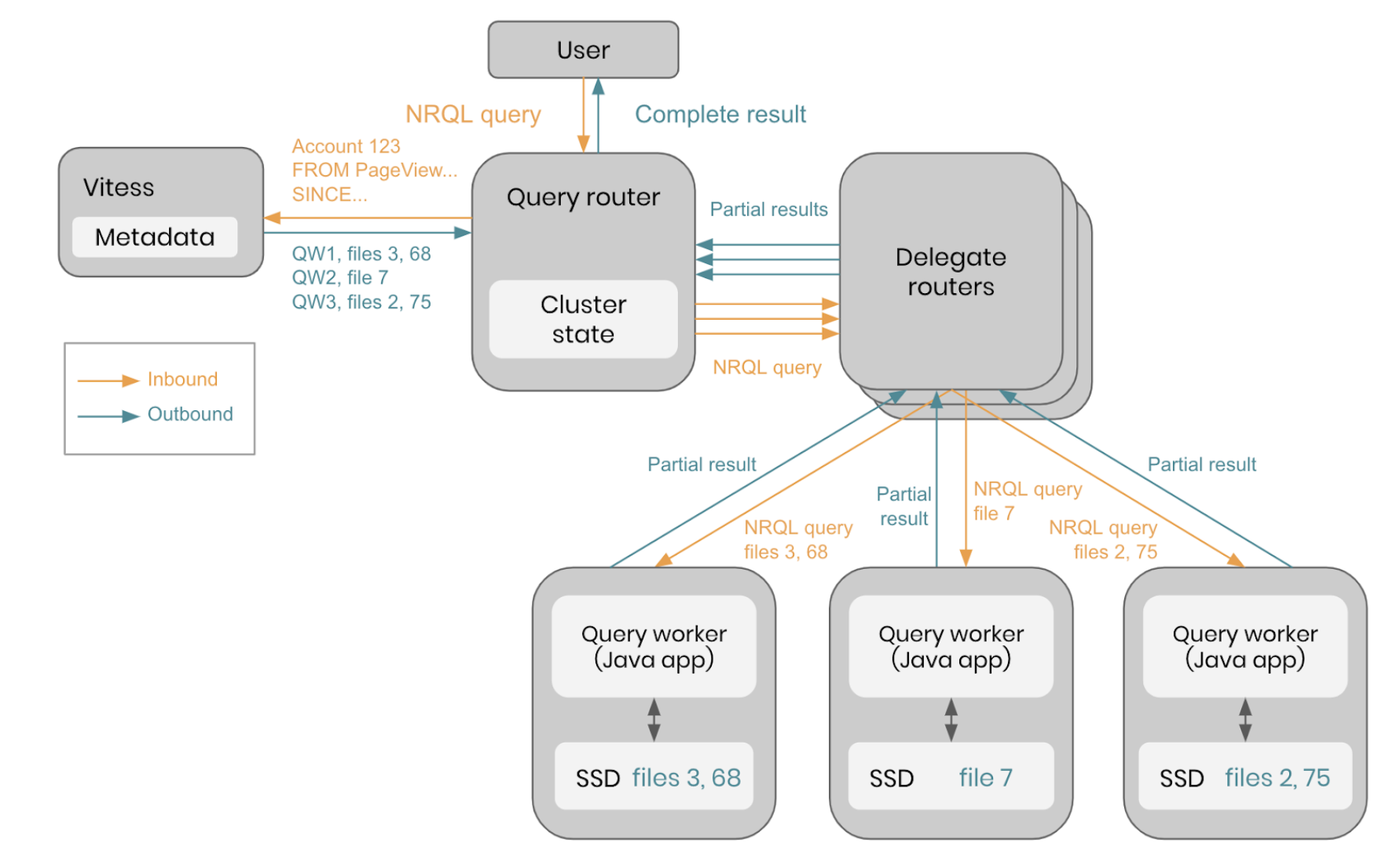
Every second, Telemetry Data Platform serves thousands of queries for our customers, who need answers stored in multiple terabytes of data. Moving all that data around to search through it doesn't make sense, so instead we take the query to the data.
Every query starts at a query router that locates the data in the cluster and sends the original query to hundreds, or even thousands, of workers to scan where the relevant data resides. To balance memory and IO needs in Telemetry Data Platform’s multi-tenant cluster, very large queries are broken up into smaller pieces. Those pieces of the query are sent to other routers that deliver their partial queries to the workers holding the data. Telemetry Data Platform’s in-memory cache provides the fastest results for recently executed queries, or the workers scan the data from disk for queries asked less often. As each worker reads its files to answer the query, the process is reversed. First, the results of each file are merged on a worker. Then, each worker’s result is merged through the routers recursively until the original router has all of the data, returning the completed answer to the user.
Additional Resources and Reading
Telemetry Data Platform is readily accessible to New Relic users, and there are a number of ways to ingest and query your data:
- Ingest your data
- Event API: Send event data to Telemetry Data Platform
- Metric API: Send custom metric data to Telemetry Data Platform
- Query your data
- Graphic UIs—create charts with ease
- New Relic One chart builder: Run queries of your data to create custom charts and other visualizations. You can also build custom dashboards containing multiple charts.
- New Relic One dashboards: Combine data from anywhere in the New Relic platform to build flexible, interactive visualizations.
- Programming APIs—write your own apps using data from Telemetry Data Platform
- New Relic One application SDK
- Insights query API: A REST API for querying your event data.
- NerdGraph: New Relic’s GraphQL API, an efficient and flexible API query language that lets you request exactly the data you need, without over-fetching or under-fetching. You can use the New Relic NerdGraph GraphiQL explorer to make New Relic Query Language (NRQL) queries.
- Graphic UIs—create charts with ease
For the NRQL language, here are a few references:
Monitor your stack for free with full platform access and 100GB of ingest per month. No credit card required.
When you know what questions you’re going to ask, it’s easy to build a database schema to return answers quickly. Unfortunately, modern systems require the ability to get answers to questions you didn’t know you had. And they demand answers now—especially when something goes wrong.
The New Relic Database (NRDB) was designed from the ground up to give a lightning-fast 131 mean response time to any question. It’s the powerhouse database driving the New Relic platform, giving you the ability to analyze 50 billion records in under 30 seconds with a single query.
And now you can take a deep dive into how it works with our new ebook. You’ll find out how:
NRDB's schema-less design gives you speed and flexibility
Using an SQL-like query language makes querying large amounts data a breeze
It supports all major telemetry types
NRDB is the world’s most powerful telemetry database. And this ebook shows you why.
Check it out for yourself!

