Introduction
The good news about microservices and distributed systems is that they enable developers to increase agility, scalability, and efficiency for customer-facing applications and critical workloads. But there’s also bad news: debugging and monitoring them is increasingly difficult as infrastructure is abstracted away from the enterprise, and applications span a collection of third-party services, legacy components, business APIs, and modern cloud solutions.
When an incident without a clear root cause arises, you may struggle to locate, diagnose, and solve an issue that could negatively impact multiple application stack layers. As a result, your company risks losing revenue and reputation as digital properties slow or fail.
The ever-expanding number of areas to monitor and react to—hybrid environments, a wider surface area, increased operational data emitted across fragmented tools, and constant alerts—is stretching teams and budgets.
Some companies have adopted dozens of commercial and open source monitoring tools in response. The end goal is better visibility across software and systems, but the array of disconnected solutions—whether for infrastructure, applications, logs, digital experience, and beyond—winds up creating tool sprawl. When this happens, engineers continuously have to switch between solutions to uncover problems, resulting in blind spots, increased toil, and unnecessary challenges, usually during critical moments.
Mounting costs—in both developer time to learn and embrace new tools as well as operating and capital expenses—are also considerations. And while open source tools can seem like opportunities to avoid vendor costs, many organizations still struggle to forecast the ultimate infrastructure and human effort required to maintain and operate these solutions.
Creating Better Software Amid Mounting Complexity
Despite these challenges, most engineers still have a similar, singular focus: Building and maintaining code that performs well in production. If something goes wrong, you need to understand, find, and fix the issue quickly.
Delivering more perfect software is a constant challenge, but the companies that do it well often see three main outcomes:
-
Improved uptime and performance. Delivering an exceptional digital customer experience that drives engagement, conversion, and brand affinity requires your development and operations teams to have the visibility and tools needed to identify, diagnose, and repair issues quickly.
-
Greater scale and efficiency. As your company grows, you must maintain a firm handle on your environments as you migrate workloads to the cloud to gain scale, re-architect applications and infrastructure, and adopt architectures such as microservices and serverless. You must also rationalize disparate tools to eliminate data silos, enable holistic visibility, and reduce costs. Our research indicates that the average respondent collects telemetry data from less than half of their systems.
-
Accelerated time to market. Today’s consumers are more demanding than ever. You must equip your development teams with data and tools to support faster feature delivery, rapid recovery, and more experimentation to drive competitive business advantages. You also must gain agility with continuous delivery practices such as configuration management, continuous integration, and automated testing. Successful DevOps teams foster a culture of collaboration and visibility, so engineers across organizational boundaries can share learnings, coordinate better, and know exactly where to focus.
To achieve these goals of improved uptime and performance, greater scale and efficiency, and accelerated time to market, software teams must prioritize observability.
Solving Modern Systems’ Challenges with Observability
Long gone are the days of infrequent, waterfall software releases in monolithic applications. Today, disparate teams continuously push software updates into production into ephemeral architectures such as containers.
The reality is that change—in infrastructure, code, and end-user behavior—is the hallmark of modern systems. And this change doesn’t inherently need to be risky. You need technology partners that can help you effectively balance system reliability with speed.
You need to see how all of your applications and their underlying services and systems relate, so you can understand dependencies across organizational boundaries, and troubleshoot and solve problems faster.
And the holy grail: You need to be able to ask ad hoc questions of your data in real time, even if—especially if—you didn’t initially anticipate needing to ask those questions. When you do that, you get observability.
Simply put, observability is how well you can understand the behavior of your complex digital system. It involves proactively collecting operational data—that’s metrics, events, logs, and traces (or MELT for short)—in one place, visualizing the connections between that data via intuitive experiences, and applying intelligence to instantly detect, diagnose, and resolve issues before your customers notice. If monitoring tells you when something is wrong, observability lets you ask why.
New Relic One: Observability Made Simple
To achieve observability, you need the right technology platform. The platform must be able to ingest telemetry data from any source, whether proprietary or open source. It must allow you to flexibly query your telemetry data and give you a rearview understanding of known unknowns, and let you interrogate the “unknown unknowns” of your dynamic systems. Cardinality can’t be a restraint.
Enter New Relic One—the cloud-based observability platform built to help you create more perfect software. It now includes three core components:
Full-Stack Observability lets you easily visualize, analyze, and troubleshoot your entire software stack in one connected experience. You can stop switching between disparate tools and trying to stitch together scattered data to figure out what went wrong. With rich analytics and a curated user experience, Full-Stack Observability surfaces the context your teams need to pinpoint and resolve problems within your infrastructure, applications, and end-user experience faster.
Applied Intelligence gives you the ability to detect, understand, and resolve incidents faster. By harnessing the power of artificial intelligence and machine learning, Applied Intelligence offers AIOps capabilities that reduce alert noise, helping you find insights in the data that would otherwise go unnoticed.
Telemetry Data Platform lets you ingest, visualize, and alert on all your metrics, events, logs, and traces from any source—all in one place. The world’s most powerful, managed, open, and unified telemetry database now comes with out-of-the-box integrations for popular open source tools to enable easy setup and eliminate the cost and complexities of hosting, operating, and managing additional monitoring systems or data stores. With all of your telemetry data in one place, you can investigate your unknown unknowns with confidence.
Full-Stack Observability
Full-Stack Observability gives you simple, intuitive, curated monitoring experiences that span your entire estate, from applications and infrastructure to logs and serverless apps, through the end-user experience. You’ll gain automatic connections to your data—regardless of telemetry type or where that data was generated in the stack—which gives you the quick context you need to navigate between common threads.
Full-Stack Observability empowers you to understand and troubleshoot problems across your entire software stack in one curated, unified experience with these foundational capabilities:
New Relic Explorer
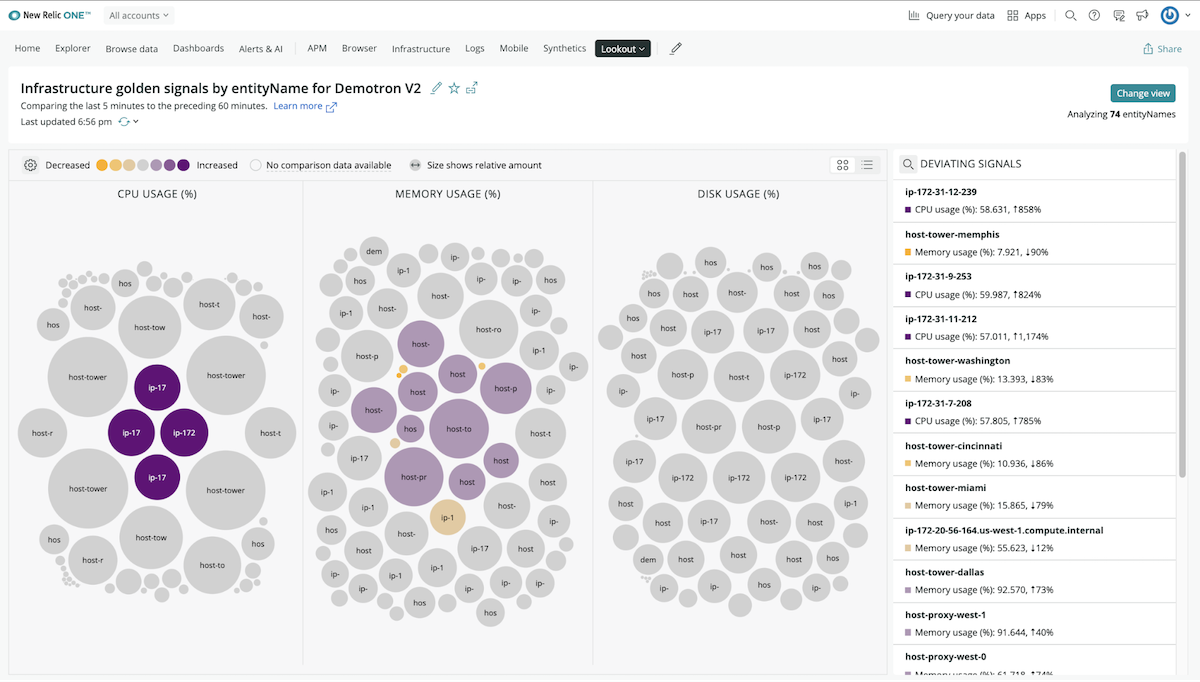
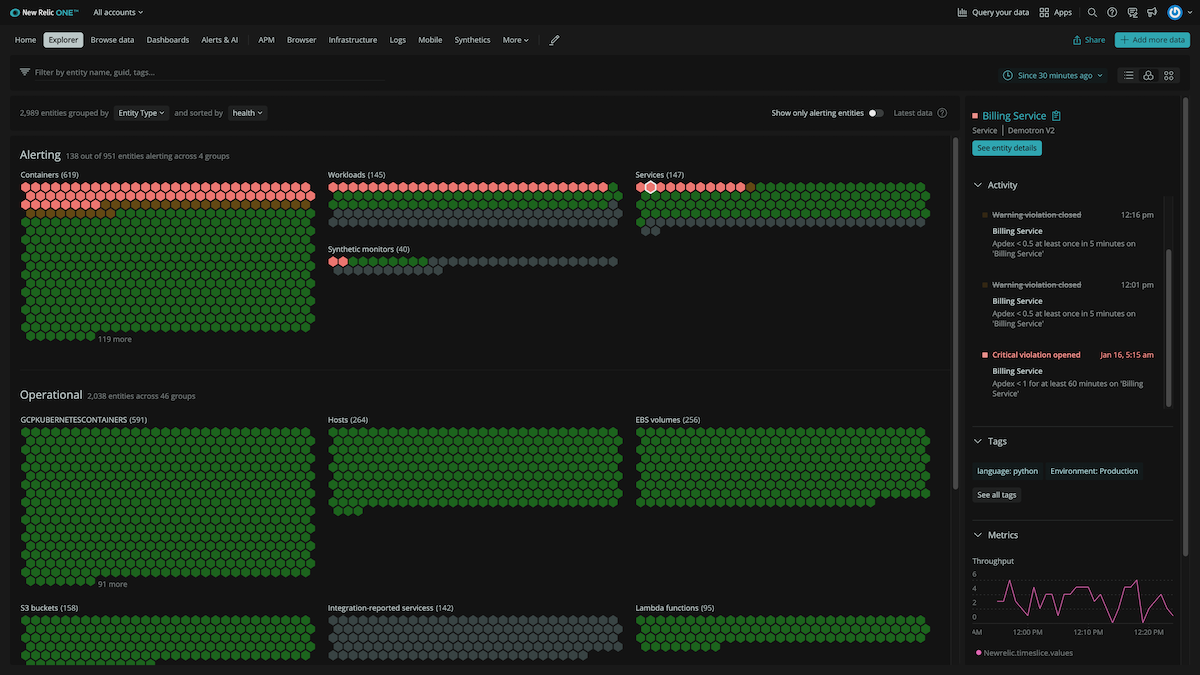
New Relic Explorer is an intuitive experience for visualizing and exploring all your telemetry data, regardless of source, from infrastructure hosts to mobile apps, distributed services to cloud APIs, and everything in between. Discover emerging issues in real time without relying on static, preconfigured thresholds or dashboards so you can get your system back to full health before your customers notice any problems.
- Get answers faster. Breaks down silos and enables teams to observe their entire system in one place so they can quickly understand health and changes across their environment and resolve issues faster. There’s no configuration needed so you can start discovering insights right away.
- See everything in one place. Provides an estatewide view of all your telemetry data with real-time change analysis that helps spot unwelcome changes to the operating environment.
- Simple and intuitive. Enables teams to efficiently traverse large distributed systems with intuitive visualizations that drive quick understanding and prioritization of any issue. You get unlimited possibilities to easily explore all your data with point-and-click filtering and grouping for all entities, by entity types or tags.
APM
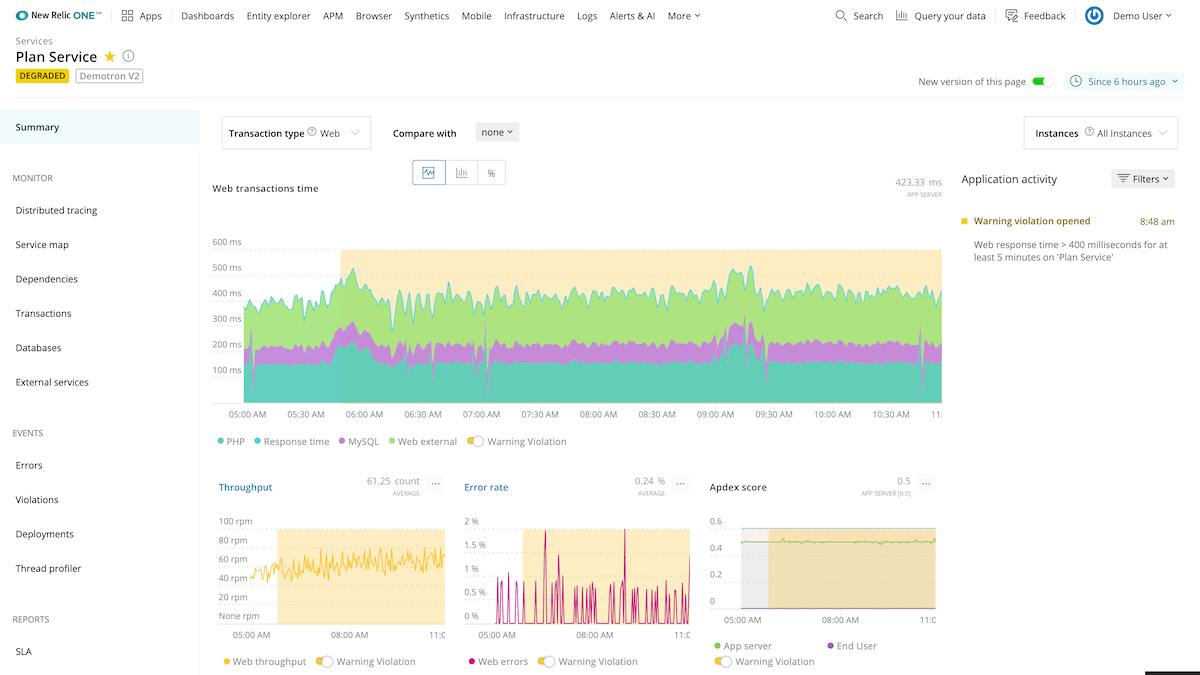
APM provides flexible, in-depth, and curated views into modern applications, regardless of how they’re developed or where they’re running. With out-of-the-box instrumentation and opinionated workflows, APM lets you quickly detect anomalies, discover deficiencies, and improve performance on key metrics for business-critical applications and distributed services. With APM, teams can:
- Rapidly ship new features. Extensive, curated visibility from a single screen reduces complexity and risk, and lets you deploy services quickly with confidence.
- Resolve problems and outages quickly. Find root causes and fix issues fast, thanks to in-depth transaction details that show exact method calls with line numbers, including external dependencies for apps of any size and complexity.
- Optimize service performance. Get a full picture by combining key metrics from mobile and browser apps with supporting services, datastores, and hosts, to optimize performance holistically.
Infrastructure Monitoring
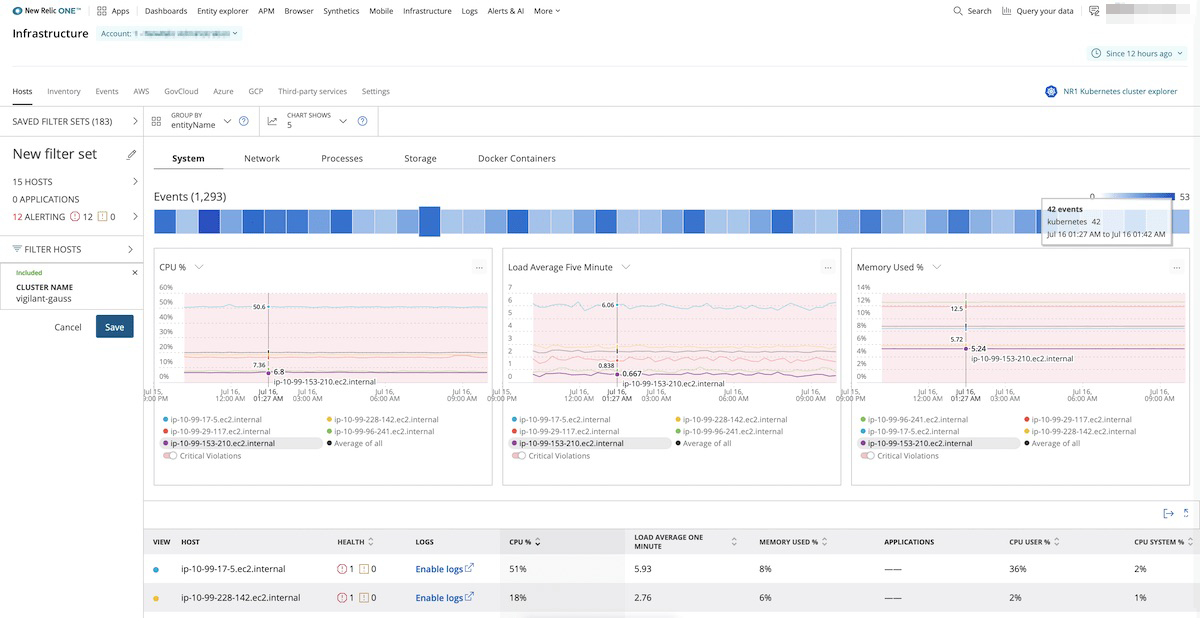
With Infrastructure Monitoring, you quickly understand what’s happening in your infrastructure, including servers running on-premises, VMs running in the cloud, containers orchestrated by Kubernetes, or any combination thereof. Intuitively monitor, manage, scale, correlate, and optimize the infrastructure that supports your applications. Specifically, with Infrastructure Monitoring, teams can:
- Prevent outages with contextual monitoring. Confidently make sense of complex relationships and dependencies in your distributed operating environment. By correlating infrastructure telemetry with logs, configuration changes, and application performance data, your teams can surface data in the right context to understand how the infrastructure and applications impact one another.
- Get multidimensional views into Kubernetes clusters. Drill down into Kubernetes data and metadata with a high-fidelity, curated UI that simplifies complex environments.
- Leverage cloud-ready integrations. Out-of-the-box integrations offer a comprehensive set of telemetry from services such as databases, web servers, network devices, search engines, queuing systems, and cloud providers.
- Search your entire host infrastructure. Infrastructure Monitoring collects detailed information about a system's configuration per host, including system modules, configuration files, metadata, packages, services, user sessions, and more.
Serverless Monitoring
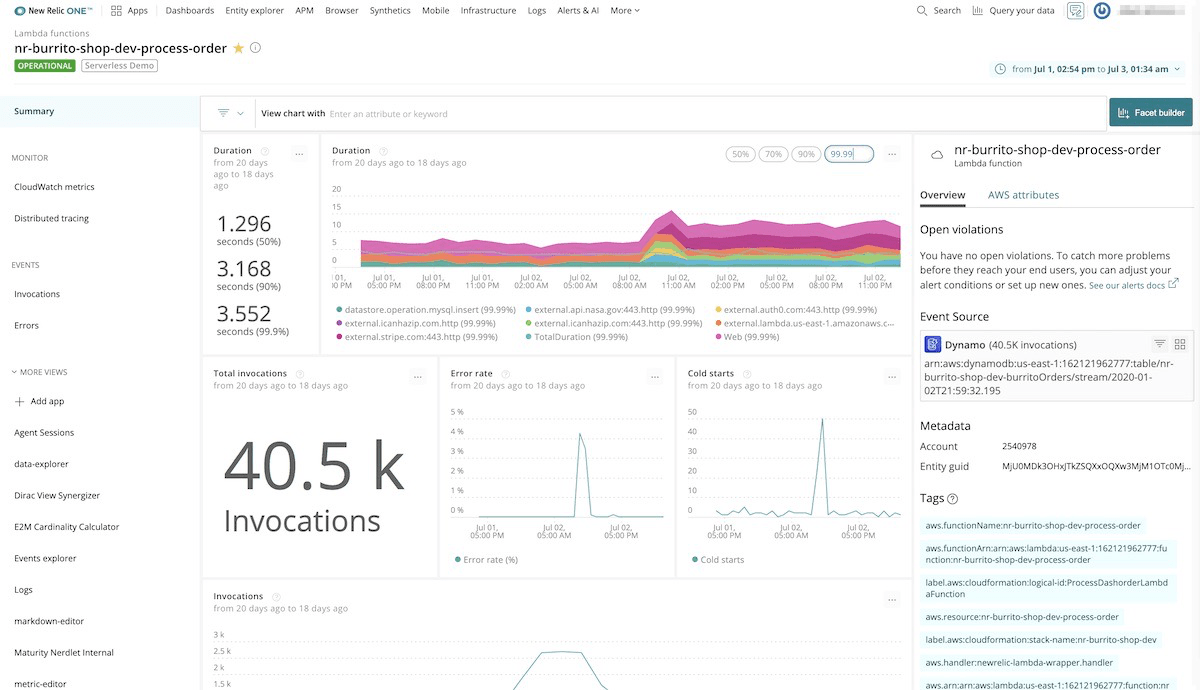
Serverless Monitoring gives unified visibility into the most detailed behaviors of your serverless applications. This capability allows your teams to function faster and deliver with assurance on serverless architectures. With Serverless Monitoring, teams can:
- Debug intelligently. Deliver serverless apps with increased confidence by rapidly identifying when problems arise and quickly pinpointing the cause—without wading through millions of invocation logs.
- Spend less time instrumenting and more time building. Rapidly auto-instrument monitoring and observability to your serverless functions without requiring code changes.
- Get unified visibility across your entire ecosystem. Serverless Monitoring gives you auto-instrument tracing for your legacy application components alongside the performance of modern serverless components—from backend infrastructure to client-side apps.
Digital Experience Monitoring
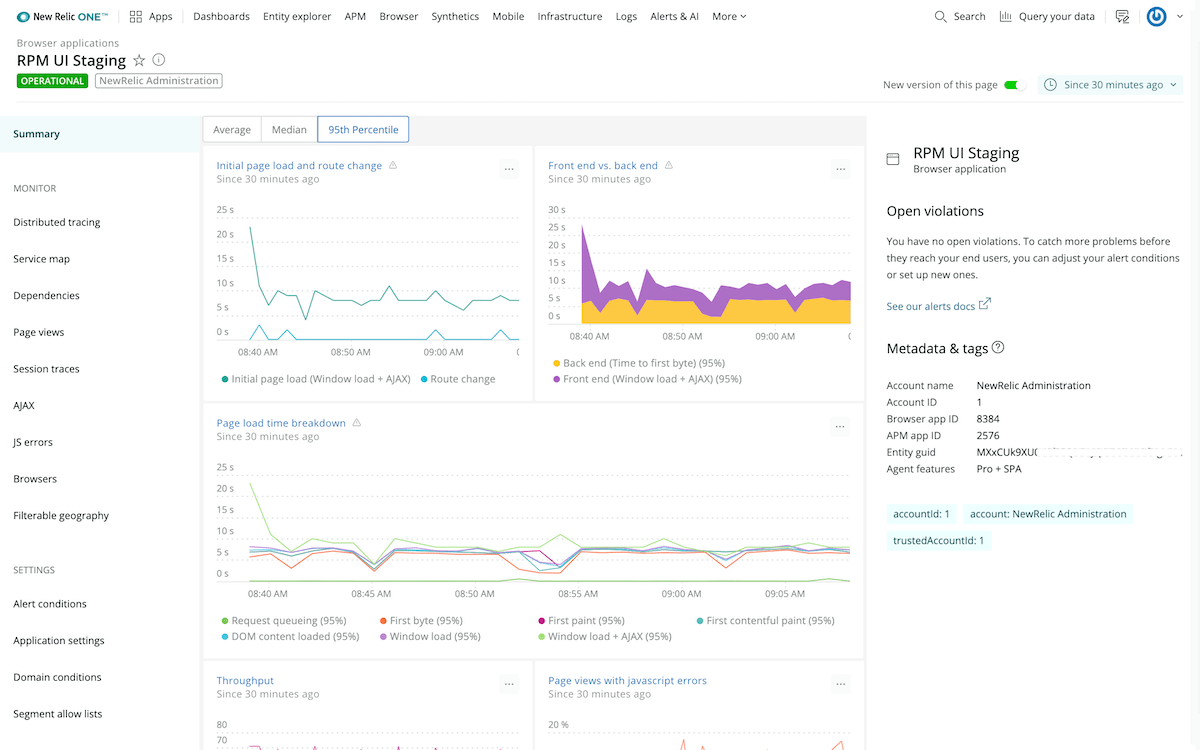
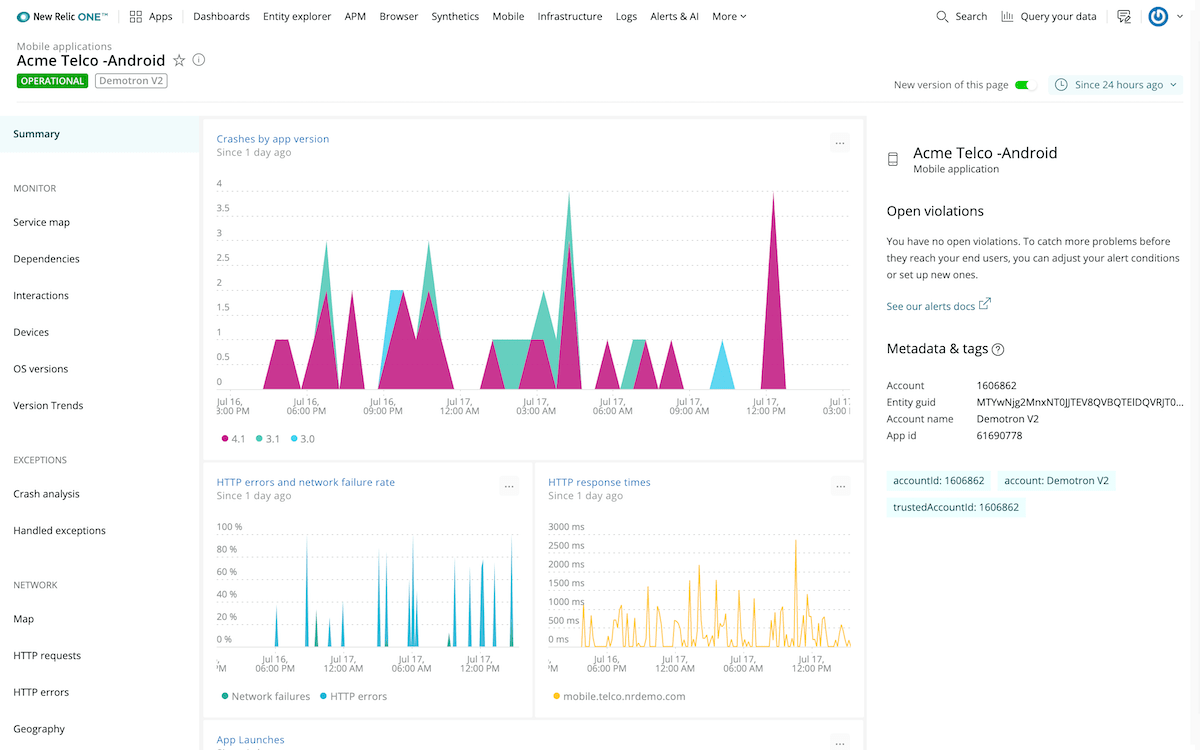
Get rapid visibility into how end users experience your mobile apps and web browsers. Analyze actual or simulated end-user behavior to hone in on metrics such as load time, availability, and errors, while staying grounded in the backend services that enable these critical digital experiences. With Digital Experience Monitoring, teams can:
- Maintain mobile app stability. Identify the crashes that are most affecting your app and fix them faster using breadcrumbs and the event trail.
- Analyze endpoint performance and latency. Detect and resolve uptime and performance issues of service, URL, and API endpoints for customer- and employee-facing applications.
- Explore end-user engagement and activity. Understand how your releases impact KPIs for your mobile app, top users, and overall business.
- Optimize customer experience (CX). Benchmark and improve site speed and performance to increase customer engagement, satisfaction, and business outcomes.
- Debug errors. Get all the tools and context your cross-functional teams require to quickly troubleshoot and resolve errors, latency, and anomalies as you make changes to Javascript and end-to-end transactions.
Logs in Context
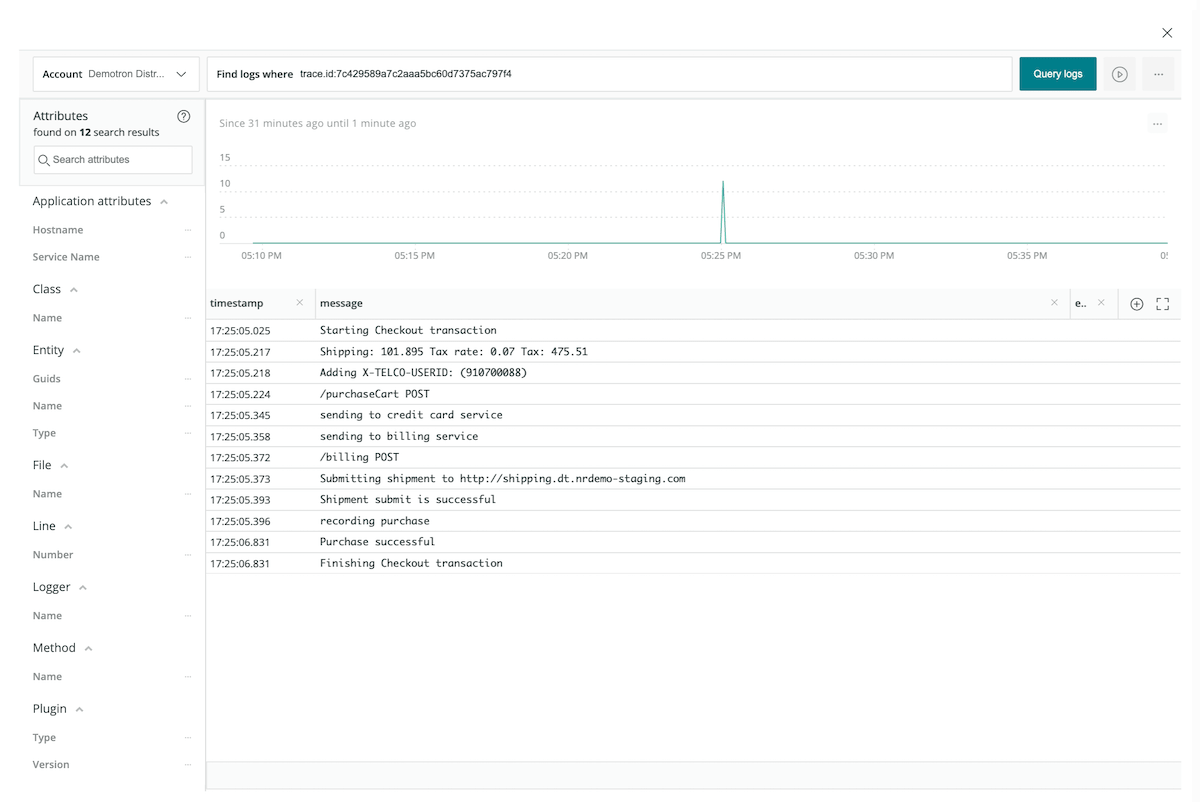
Logs in Context offers visibility into any text-based data or data that can be converted to text originating either on-premises or in the cloud. With Logs in Context, teams can:
- Troubleshoot faster. Combining logs with other telemetry data types enables complete observability. With correlated log visibility at scale, teams can troubleshoot distributed systems faster and reduce mean time to detection (MTTD) and mean time to resolution (MTTR). A single click takes you from errors, traces, or spans to the correlated logs for quick root cause analysis.
Applied Intelligence
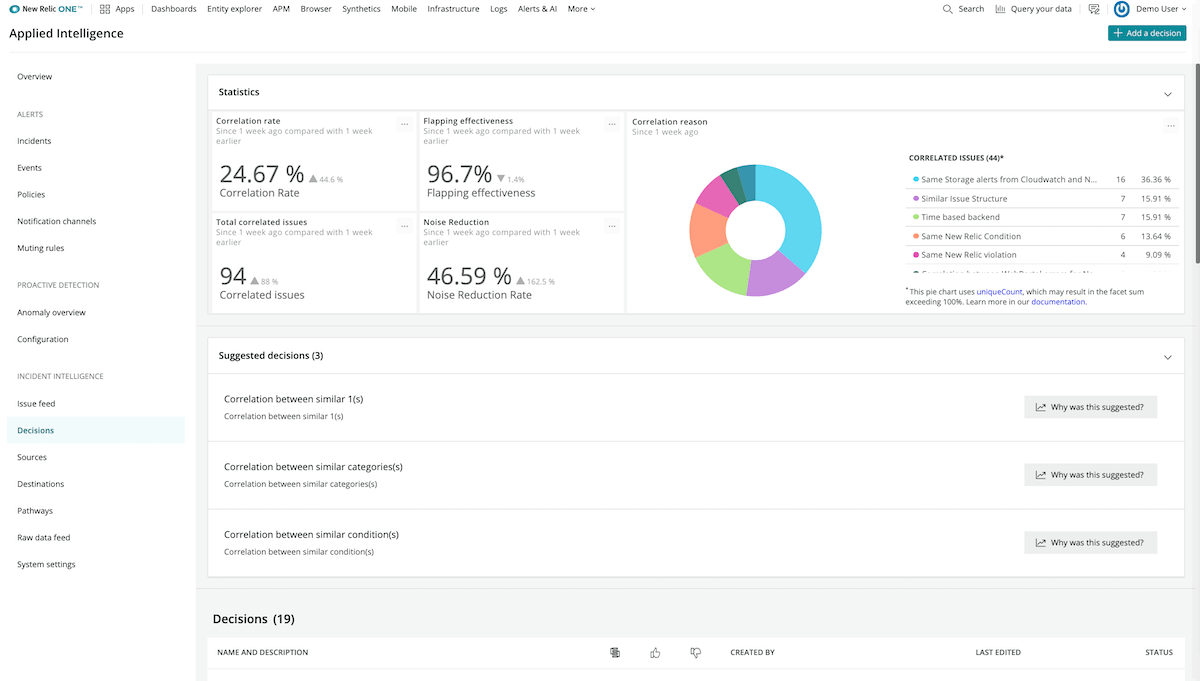
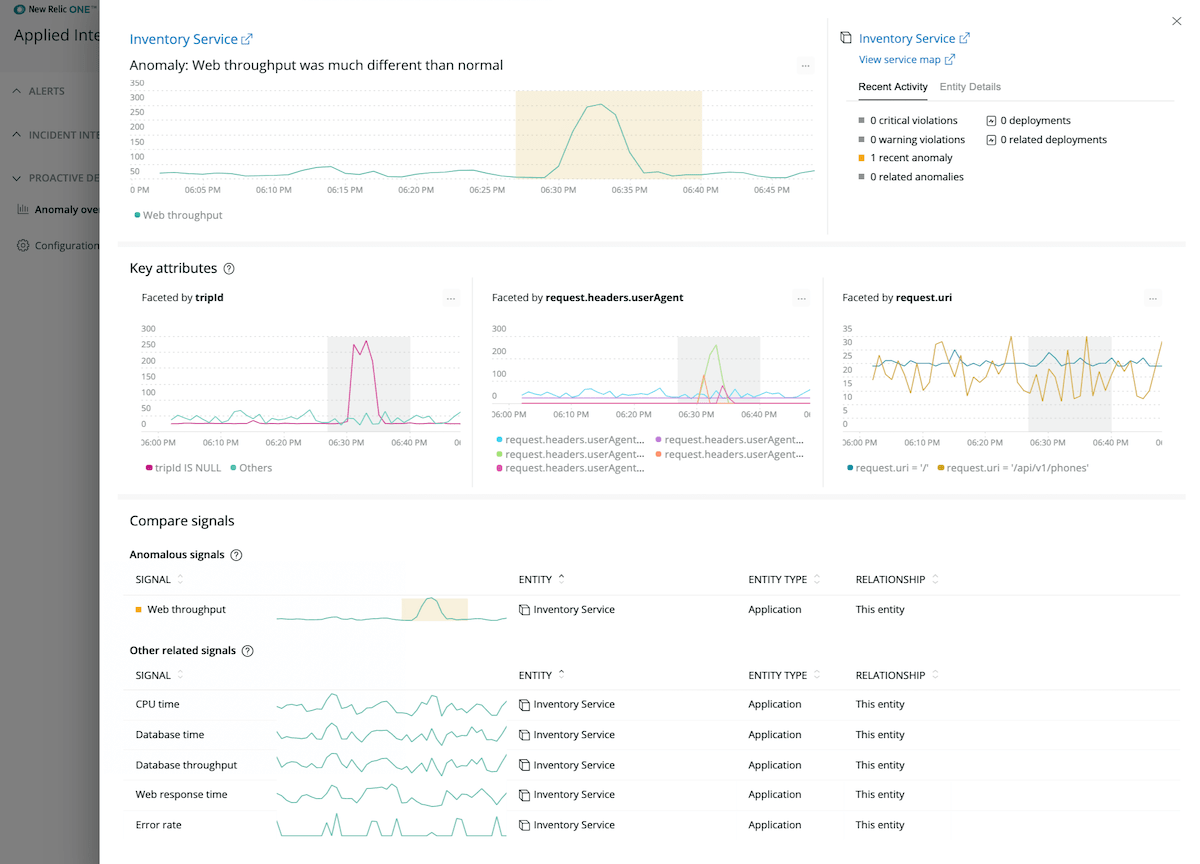
Detect, understand, and resolve incidents faster with the easy-to-use, powerful Applied Intelligence capabilities that quiet alert noise and deliver critical data observations that you would otherwise miss without the assistance of machine learning.
Applied Intelligence benefits and capabilities include:
- Faster to connect, gain value. Connect the tools (Slack, PagerDuty, Splunk, Grafana, Prometheus, Amazon CloudWatch) you already use in a few clicks with our guided configuration UI, webhooks, and APIs. Ingest alerts, incidents, and event data from any source.
- Automatic anomaly detection with context. Proactively monitor your services for anomalies based on Site Reliability Engineering (SRE) golden signals—such as latency, errors, and traffic—and get notified with real-time failure warnings and anomaly analysis to troubleshoot faster.
- Reduce alert noise and fatigue. Establish relationships among incidents, including flapping detection and smart suppression to reduce noise from low-priority, auto-resolving alerts by as much as 90%.
- Infuse correlations with decision logic. Quickly build correlation logic with an intuitive decision builder that tells AI what data to compare, correlate, the maximum time period to consider, and the minimum number of alerts to correlate. You can even choose specific out-of-the-box similarity algorithms to use, giving you full power and control.
- Total transparency into incident correlation. Get full transparency into why and how correlations perform to provide confidence and reduce noise while ensuring that critical signals don’t go unnoticed.
- Diagnose and respond faster with incident intelligence. Enrich correlated incidents with deeper context and metadata to troubleshoot and understand issues, get closer to the root cause, and resolve them faster.
- Escalate incidents to the right responders faster. Route correlated incidents to the team members best equipped to respond, thus making noisy, misdirected alerts a thing of the past.
- No changes to your existing incident response workflow. Deliver correlated, enriched incidents into tools such as PagerDuty, OpsGenie, ServiceNow, and more, so you don’t need to reinvent incident response.
Telemetry Data Platform
The capabilities, features, and experiences in Full-Stack Observability and Applied Intelligence are all powered by the Telemetry Data Platform, a massively scalable, time-series database that lets teams collect, explore, and alert on all metrics, events, logs, and traces from any source—all in one place.
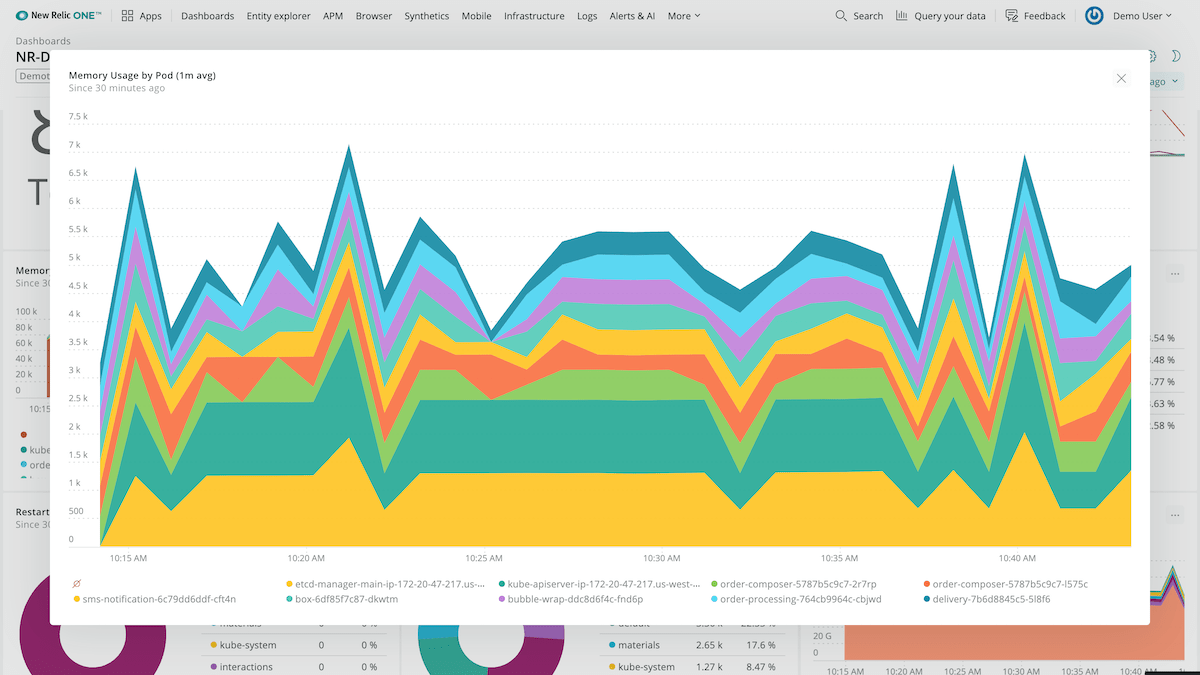
Telemetry Data Platform benefits include:
- SaaS platform. Highly available, resilient, scalable, powerful, SaaS platform with long-term retention, so you don’t need to operate and manage additional systems.
- Open, unified telemetry database. One place to ingest, analyze, visualize, and alert on all metrics, events, logs, and traces, so you can build dashboards to understand and resolve issues faster than ever.
- Enterprise-grade. Built and operated with the highest security and encryption levels, including encryption at rest and role-based access control (RBAC), to ensure you meet regulatory and compliance requirements—such as FedRAMP moderate impact level and General Data Protection Regulation (GDPR). Dedicated experts are available 24x7 via customer support.
- Comprehensive and future-proof. Benefit from the innovation of New Relic’s dedicated development teams as well as the open source community that is building a wide range of solutions.
Gain visibility into your complex systems with New Relic One
New Relic One makes it easy for engineers to spend less time troubleshooting and more time building more perfect software. It’s a massively scalable, extensible SaaS platform that can collect all infrastructure and application data, quickly visualize that data in connected views, and apply machine learning techniques to deliver benefits such as anomaly detection, event correlation, and alert suppression. Welcome to the age of observability for all.


