Infrastructure monitoring is software that helps you monitor, quickly pinpoint, and fix issues across your entire infrastructure—including cloud-based services, on-premises hosts, orchestrated containers, and virtual machines. You can use infrastructure monitoring to get complete observability of complex and hybrid systems such as data centers and cloud-based services like Amazon Web Services (AWS) and Microsoft Azure. You can also use infrastructure monitoring to give you a high-level view of your system’s CPU, RAM, storage, and network traffic.
Read on to learn more about infrastructure monitoring, including why it’s important and what you should look for in an infrastructure monitoring tool.
What is application infrastructure?
Application infrastructure is all of the assets that allow your systems and technology to function, including networks, hardware devices, and servers, whether they are based in the cloud or on-premises. Even if you’re using cloud solutions, that infrastructure is still based on a physical server somewhere. Application infrastructure is like a building’s foundation—you can’t see it, but it’s supporting the entirety of the building.
Ultimately, you can think of application infrastructure as consisting of three layers:
- Hardware: The hardware includes all of the physical components that host your infrastructure. It includes the physical servers and the processors, network devices, and other physical devices that your system uses. This layer is ultimately built on microchips, including logic chips (CPUs) and memory chips (RAM). There are other types of chips, too, including neural processing units (NPUs), which are designed for machine learning applications.
- Operating system (OS): The operating system provides an interface that connects the two layers of application infrastructure: the hardware and the application itself. The operating system executes applications while also using hardware resources such as CPUs and RAM. This also includes virtual machines, which have their own operating systems.
- Application: This is the application itself, which could be a custom application you’ve developed or an application that uses a content management system like WordPress. The application layer also includes containers, which are used to run many applications.
If you’re using on-premises servers, you need to think about all of these layers, including making sure your hardware is functioning properly. With cloud-based infrastructure, you no longer have to worry about hardware in the same way, because your cloud provider maintains the infrastructure that hosts your software and applications. However, you do still need to think about provisioning resources—CPU, memory, storage, and networking. If your application is underprovisioned, it won’t function properly, and if it’s overprovisioned, then you’ll be wasting money on capacity you don’t need.
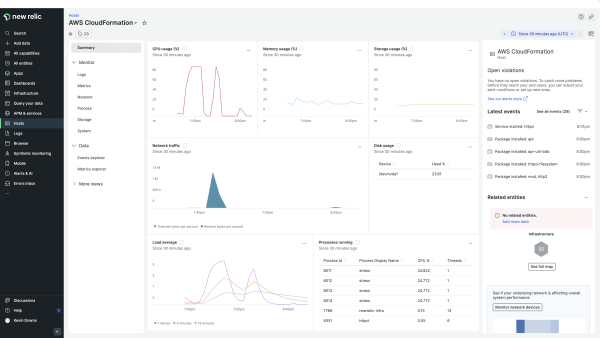
The next image shows a dashboard in New Relic Explorer with a high-level view of containers, services, hosts, and more.
Why is infrastructure monitoring important?
Regardless of whether your applications use cloud-based or on-premises hosts (or both), infrastructure provides the foundation for your systems. Just as a train can only operate on tracks that are well-maintained, your system needs performant, reliable servers to ensure that services are delivered to your users. When infrastructure goes down, your application's performance suffers and you might even have outages. Because the stakes are so high, maintaining infrastructure can be both challenging and stressful. Even if your servers have nearly 100% uptime, the outages that do occur can be severe. Outages and downtime impact your authority and your users’ trust. At best, your users can’t access your services during an outage, and at worst, your users get frustrated and don’t return.
While you can monitor things like a system’s CPU and RAM on an operating system command line, you need a more comprehensive solution for monitoring application infrastructure, especially as your applications get larger and more complex. That’s where infrastructure monitoring tools come in. An infrastructure monitoring tool like New Relic allows you to visualize your entire system’s infrastructure from one place, including metrics, events, logs, and traces (MELT).
Infrastructure monitoring is just one part of a complete observability practice. Observability is about proactively collecting, visualizing, and alerting on data across all of your systems, including your infrastructure. Ideally, the platform you use should also monitor other aspects of your application, including application performance. That way, you can pinpoint and fix errors that arise in your infrastructure and elsewhere in your applications.
Benefits of infrastructure monitoring:
- Find and fix outages and other infrastructure-related issues quickly.
- Support your engineering, DevOps, and IT teams that work with and are reliant on application infrastructure.
- Provide end users a consistent, positive experience, which in turn positively impacts the bottom line.
What can you monitor with an infrastructure monitoring solution?
An infrastructure monitoring solution allows you to monitor all parts of your application infrastructure. In the case of New Relic, you get the following by default once your infrastructure is instrumented:
- The current state of the server, including CPU, memory, disk, and network.
- The usage and capacity of a storage device associated with the server.
- The usage data for each network device associated with the server.
- Data on all Docker containers and Kubernetes clusters, including metrics about CPU, memory, and networking.
- Any changes in a system’s live state, which is stored in an
InfrastructureEvent.
In addition to instrumentation, you can also use integrations to analyze, visualize, and alert on data from other parts of your infrastructure. New Relic has two main categories of infrastructure integrations:
- Cloud integrations with services such as AWS, Azure, and Google Cloud Platform.
- On-host integrations with services such as NGINX, MySQL, Redis, Kafka, and Apache.
An infrastructure monitoring platform should also provide enough flexibility for your own custom solutions. You can even get creative and monitor the infrastructure in your home environment, too. Here’s how an engineer used New Relic to monitor his home solar array.
The next image shows an example of monitoring Kubernetes clusters in New Relic Explorer.
How does infrastructure monitoring work?
Like other types of monitoring, infrastructure monitoring usually involves instrumenting a host by installing an agent. In the case of a monitoring solution like New Relic, you can begin the process of instrumentation with a simple guided installation. The agent automatically detects the application and log sources running in your environment and then recommends which ones you should instrument.
Once your hosts are fully instrumented, the agent will collect system data and send it to your infrastructure monitoring solution. In some cases, the agent will forward data and logs, particularly in the case of integrations.
The following chart shows how a New Relic on-host integration receives data from a service like Redis or Apache.
Like other types of application monitoring, infrastructure monitoring involves data from MELT— metrics, events, logs, and traces.
Logs, which are discrete actions that occur in an application, are the building blocks of metrics, events, and traces. They are made of single lines of text. For instance, a NGINX server will log all transactions that occur. Events can consist of many lines of log data. Along with traces, which connect events together, events provide more context on what is happening in your infrastructure.
Finally, metrics are aggregated data, giving you a high-level view of what’s happening in your application. An example is the average latency of a service over the last seven days. Metrics paint a bigger picture for you and are especially helpful for visualizing the overall health and performance of your infrastructure.
Get started with infrastructure monitoring. Try New Relic.
The best way to learn more about infrastructure monitoring and observability is to get experience with an infrastructure monitoring solution. Sign up for the free tier of New Relic to get started, then take a deeper dive into our infrastructure monitoring documentation and infrastructure monitoring best practices. You can get hands-on practice with infrastructure monitoring through this Identify root cause issues in your infrastructure lab.

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.
.png?h=d1cb525d&itok=rsVYZhw2)
